はじめに
この記事では、Visual Studio Code(以下VSCode)の拡張機能の1つを使った際の所感を紹介する。
私は普段、画像系の機械学習タスクに取り組む時VSCodeで開発している。 その際、画像に対して自前実装の前処理やデータオーグメンテーションがちゃんと施されているかを簡易的に確認したい場合がある。
そういう時に私はこれまでディスクに書き出して結果を確認していた1:。 しかし、もう少しスマートな方法がないかと思い、デバッグ中に画像を可視化できるVSCodeの拡張機能が無いか探したところ、下記の拡張機能を発見した。
VSCodeでこの名前で拡張機能を探せばヒットする。かなり長い名前なので、以下でもこのsimply-view-image-for-python-debuggingのことを「拡張機能」と呼ぶ。
スポンサードリンク
拡張機能の使用方法
公式リポジトリのgifアニメをそのまま引用するが、これを見れば使い方は一目瞭然である。
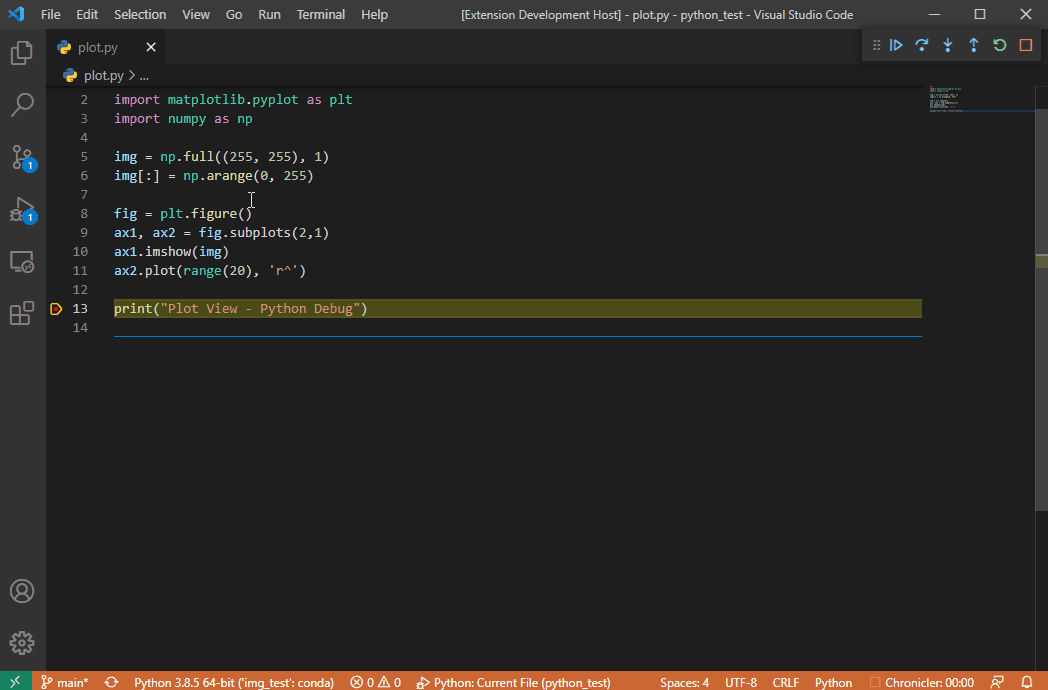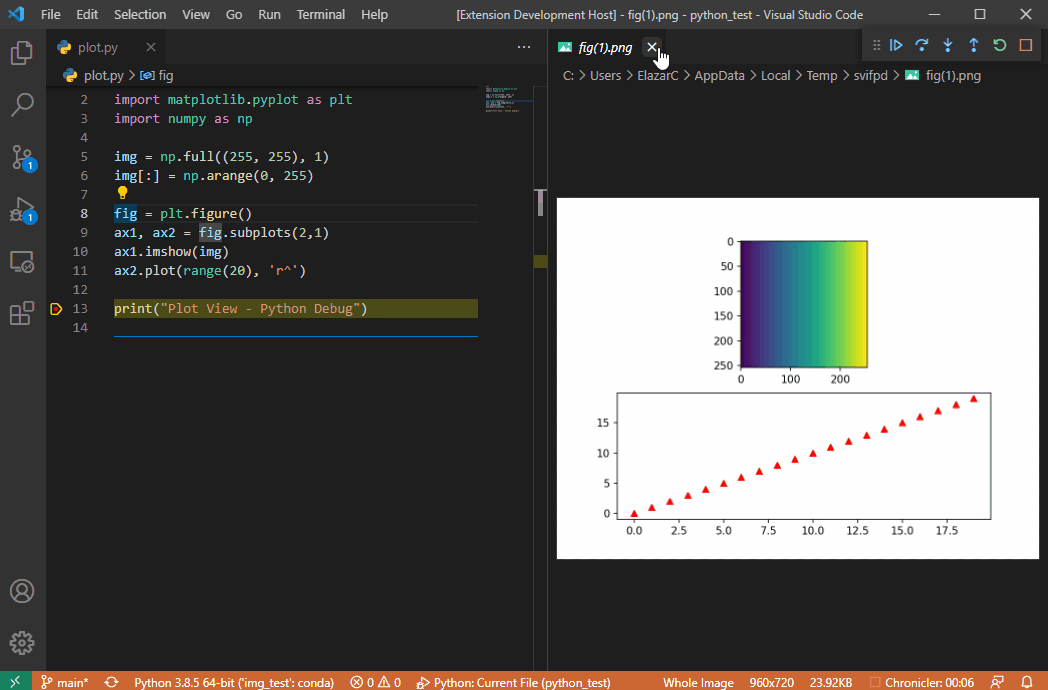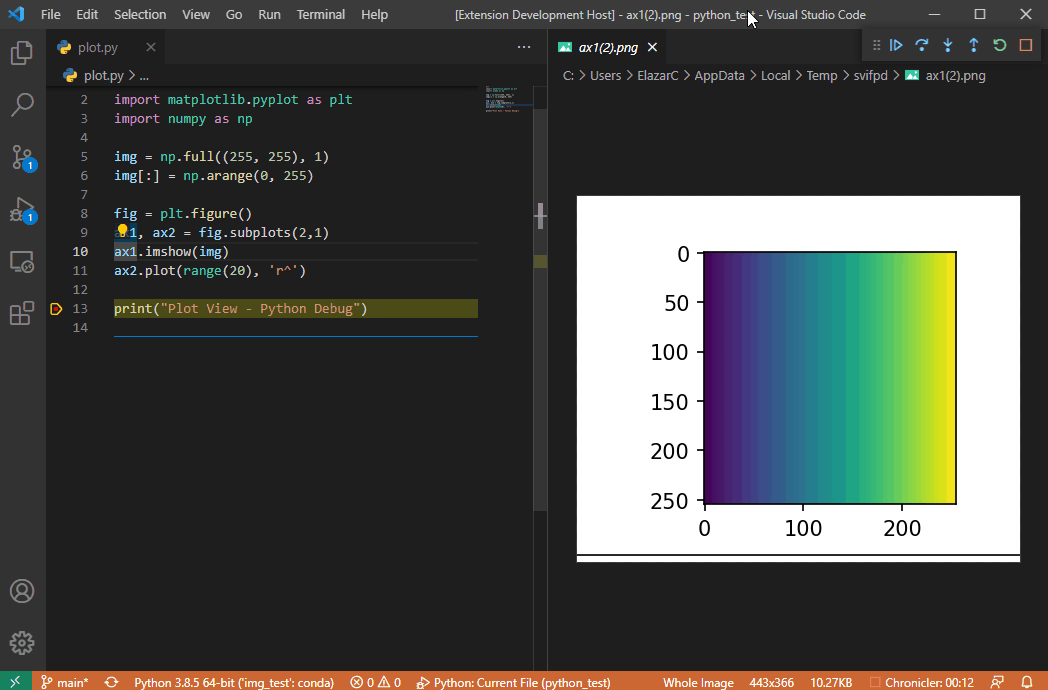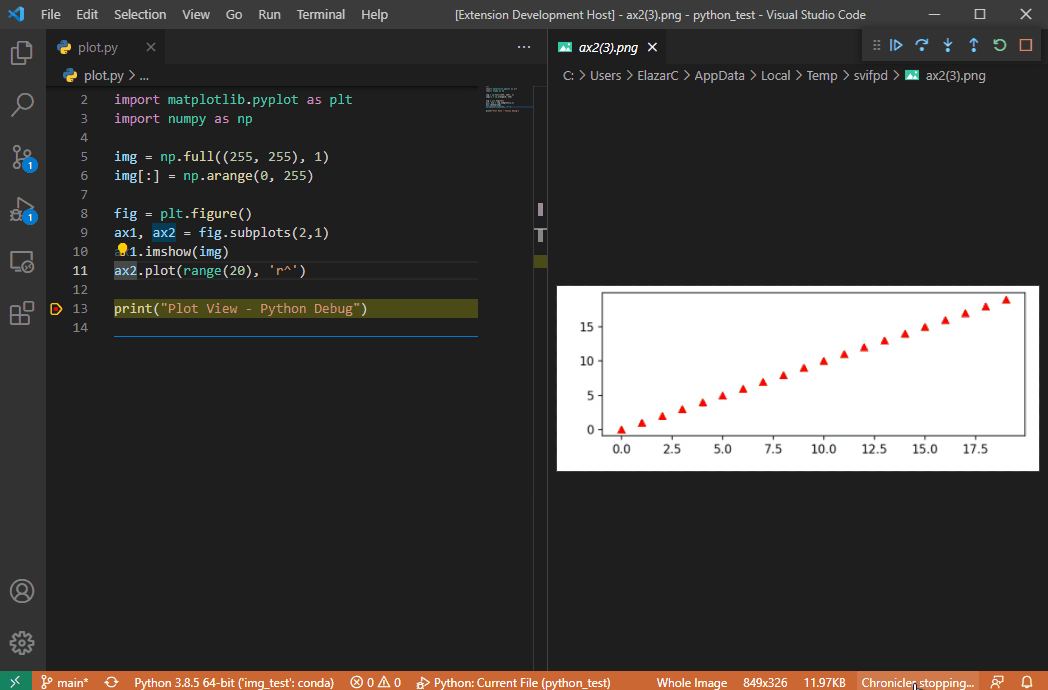
- 実行したいPythonスクリプトを用意する。
- ブレークポイントを張る。(当たり前かもしれないが)ブレークポイントの位置は、画像を可視化したいオブジェクトを変数に格納した以降の行に張ることに注意。
- VSCodeでデバックモードを実行し、処理がブレークポイントまで達したら、
- 画像のオブジェクトが格納されている変数をクリックすると、もしもその変数が拡張機能で可視化をサポートしているオブジェクトならば、電球マークが現れる。
- 電球マークをクリックすると、
View Imageというポップアップが出る。 - ポップアップをクリックすると、別ウィンドウで可視化された結果が表示される。
拡張機能内部で行われている処理はとてもシンプルで、 /tmp 領域にsvifpdと2いうディレクトリを作り、画像をそこに書き出して、その画像を別ウインドウで表示するというものである。
各ライブラリのオブジェクトの可視化結果結果
機械学習の画像系タスクで主に使用されるであろうPythonライブラリのオブジェクトを可視化した結果をスクショ付きで述べる。
各ライブラリごとの可視化結果を下表に示す。中には画像処理用途とは限らないものも含めてしまっているが、実用途を鑑みての判断であるのでご了承いただきたい。
| ライブラリ名 | 可視化可能か | 検証した際のバージョン |
|---|---|---|
| Pillow | ○ | 7.1.2 |
| NumPy(, Scipy) | ○ | 1.19.5 |
| opencv-python | △ | 4.1.1.26 |
| imageio | ○ | 2.4.1 |
| Matplotlib | ○ | 3.4.2 |
| PyTorch | ○ | 1.6.0(torchvisionは0.7.0) |
| TensorFlow | ✕ | 2.7.0 |
なお、その他の動作環境のバージョンは下記の通り。
Pillow・・・○
readmeにはサポートしているとは書いていないが、可視化可能。
NumPy(, Scipy)・・・○
画像ではなく単なる数値のテンソルに対して可視化をおこなってみたが、可能だった。 また、ScipyもNumPyを内部で利用しているので可視化可能。
opencv-python・・・△
NumPyがサポートされているので、もちろんopencv-pythonの可視化も可能。
ただし、opencv-pythonではChannelの順序がBGRなので、残念ながらきれいに表示されないところが玉にキズ。
imageio・・・○
私は使わないが、imageioを試してみた所、可視化可能だった。
Matplotlib・・・○
画像を扱うためのライブラリでは無いが、先程張ったgifアニメの通り、MatplotlibのFigure、Axisの可視化も可能。
PyTorch・・・○
readmeにはPyTorchのテンソルもサポートしていると書かれていたので試してみたが、確かに可視化された。PyTorch民としてはかなり嬉しい。
また、驚いたことにBatch次元を考慮して表示してくれている。
TensorFlow・・・✕
readmeにはサポートしているとは書いていないが念の為可視化を試みた。
しかし、電球マークが現れなかったので対応していない模様。なお、私はTensorFlowはほぼ使用経験がないので画像のテンソルを作る方法が正しいかは自信がない。
おわりに
デバッグ時に様々なライブラリのオブジェクトに対して画像の可視化を試みた。
その結果、おおよそのライブラリで可視化可能ということがわかった。
Python開発の生産性の向上が期待できそうである。
なお、今回テストに使用したコードと画像は↓のリポジトリに置いているので、興味を持たれた方は追試に使っていただければ幸いである。 github.com
スポンサードリンク










![改訂2版 基礎から学ぶVue.js [2.x対応! ]](https://m.media-amazon.com/images/I/51IaAnLCNdL._SL500_.jpg "改訂2版 基礎から学ぶVue.js [2.x対応! ]")