Trace Labs の Search Party 2024年度 参加ふりかえり

目次
記事概要
カナダのNPO "Trace Labs"が定期開催するOSINTコンテスト『Search Party』 に2024年度 全4回参加した際のふりかえりを行う。
この記事を書いている今は2025年9月であり、大分期間は経ってしまったが、コンテストを通して公開情報を調査する際のマインド面で大切な学びがあったので今更を承知でまとめることとした。
※ コンテストの基本情報から説明しているためこの記事は約2万文字ある。 何をやらかしてそこから何を学んだかは 「2024.04(2Q) 参加分」、 その経験をどう活かすに至ったかは 「2024.11(4Q) 参加分」 を参照いただきたい。
はじめに
私は公開情報の調査スキル向上を目指して、しばしばOSINTを銘打つコンテストに参加している。その中で、Trace Labs という団体が Search Party というコンテストを定期的に開催することを知っていた。
Search Party が 一般的な OSINTのコンテストと一線を画す点として、現実の現在進行中の失踪事件を調査する点である。
興味本位で2022年ごろから5回程度参加申し込みはしたものの、得点を取るどころかどうプレイすべきなのか勝手が全くわからなかった。一般的なOSINTのコンテストのようにぶっつけ本番の参加で成功体験を得られるわけではなく、参加する数を増やしても要領を掴むことができなかった。
したがって、2024年から本腰を入れてルールの理解と戦い方を覚えて、万全に準備して取り組むこととした。
Trace Labs および Search Party について
まずは、コンテストについて運営する団体を含めて紹介する。
運営組織 Trace Labs について
運営組織であるTrace Labsについては 公式HP を見れば詳しく載っているが、公式の動画(10:55の部分)によると次の通りである。
Trace Labs is a Not-For-Profit organization with a mission to crowdsource the collection of Open Source Intelligence (OSINT) to generate new leads on missing persons cases. Started in 2018, Trace Labs has grown from being Canadian based, to being a globally recognized brand.
[機械翻訳]:
Trace Labsは、オープンソースインテリジェンス; OSINT の収集をクラウドソーシングすることで、行方不明者事件に関する新たな手がかりを生み出すことを目的とした非営利団体である。2018年に設立された同組織は、当初はカナダを拠点としていたが、現在では世界的に認知されたブランドへと成長を遂げている。
- Discord上でコミュニティを運営している。
- 普段は行方不明者捜索を目的とした情報交換がなされている
- Search Partyのスケジュールはこちらでアナウンスされ、Search Party開催中は臨時チャンネルが開設され、コンテストに関する議論や振り返りを行う場が用意される
- 参考: サーバ招待リンク: https://tracelabs.org/discord
- 補足
- コミュニティではかつて"Meow"というアカウント名の方がコミュニティリーダーを務めていたが、もちろん私ではない1。
以下ではコミュニティ内で使われる略称である、Trace Labsを"TL"、行方不明者(Missing Person)を"MP"と呼ぶ。
Search Partyとは
本記事のメイントピックである、OSINTコンテスト Search Party について概要やルールについて解説する。
Search Partyの基本情報
- Search Partyとは
- TLの紹介文にもあった通り、MP捜索のための 、コンテスト形式のクラウドソーシング活動である。
- 公開情報からMPの捜査に役立つ情報を見つけ洞察のあるintelligenceを投稿するほどポイントを獲得できる形でポイントの多寡を競うコンテストとなっている。
- ただし、TLはSearch Partyのことを「ゲーミフィケーション」と位置づけており、コンテスト形式ではあるが、現実の捜索活動であることに釘を刺している2。
- もちろん、コンテストで提出された intelligence はTL運営を通して法執行機関へ提出される。
- したがって、得点を得るためだけに、見つけた関連情報を片っ端から投稿することは禁止されている。
- TLの紹介文にもあった通り、MP捜索のための 、コンテスト形式のクラウドソーシング活動である。
- 初出は2018年
- 実施形態は Grobal or 現地
- Grobal は オンラインイベントで世界中のプレイヤーが参加できる
- 4半期に一回開催される傾向がる
- ただしここ数年は様々な事情で、開催が急遽取りやめになることがある。
- 4半期に一回開催される傾向がる
- 現地開催は、BSidesやDEF CONなど、現地のサイバーセキュリティイベントにおける1つのイベントとしても開催される
- 本記事ではGrobalについて説明する。ただし、現地もルールは共通しており、どこで参加するかという違いでしかない。
- Grobal は オンラインイベントで世界中のプレイヤーが参加できる
- 開催日は現地時間で土曜日
- 毎回、特定の地域のプレイヤーが参加しやすいようにコンテスト開始時刻が変わる
- ただし、日本時間では深夜帯(大体日曜日の00:00〜7:00のいずれか)にコンテストスタートになるので、朝型の日本人にとっては厳しい時間帯であることが多い。
- コンテスト開催時間: 4時間
- チーム人数上限: 4人
- 参加費: 20$
- 参加方法
- イベントの1~2週間前に eventbrite 上で参加チケットが販売される
- なお、「コーチ」4というロールのボランティアで参加することも可能
- コーチは、プレイヤーが提出した intelligence が妥当かどうかを判断し、受理/拒否を行う役割を担う
- こちらもコンテストの2週間前ごろにgoogleフォームで一般募集され、ガイダンスを経てコンテストに臨む。
Search Partyのルール
Contestant Guide の情報の要点を絞って説明をする。
- プレイヤーは運営によって指定されたMPに関してweb上を調査し、捜索に有用な intelligence を提出する
- その提出物をコーチが確認し、intelligenceであるとみなせば投稿が受理されポイントを獲得できる。
- コンテスト終了時に得点の高い上位3チームが受賞。
- 提出できるintelligenceのカテゴリと獲得ポイントは次の通り。捜査上重要になるものほどポイントが高い。
- MPの友人(10pt)
- MPの家族(20pt)
- MPの仕事関係の情報(15pt)
- MPに関する基本情報(50pt)
- SNSアカウント、運営しているwebサイト、メールアドレスなど
- MPに関するより詳細な(advanced)情報(100pt)
- 身体的特徴、どこへ消えたのかを示唆する投稿、車のナンバープレートなど
- 公式の失踪情報には記載されていない情報(300pt)
- 公式の失踪日よりも新しいMPの活動情報(700pt)
- ダークウェブに関するもの(1,000pt)
- 人身売買など
- MPの現在いる場所(5,000pt)
- intelligence を提出する時は 1件につき どのカテゴリかと3つのテキストフォームを埋める必要がある。必要ならば画像を(1枚だけ)提出できる。
- テキストフォームのプレースホルダーにかかれている説明文を引用する。参考までに日本語訳も載せる。
- URL: The URL where this intelligence can be found.(このintelligence が見つかるURL。)
- Relevance: Reasons why this intelligence is relevant to the case.(この intelligence が本件に関連している理由。)
- Supporting Evidence: How did come to the conclusion that this intelligence is valuable. You are permitted to add additional supporting URLs here:(この intelligence がいかにして価値があると結論付けられたのか。ここに追加のサポートURLを追加することが可能)
- テキストフォームのプレースホルダーにかかれている説明文を引用する。参考までに日本語訳も載せる。

- どのような提出物を想定しているかは TL公式のブリーフィング動画 が参考になる。

くどいように何度も太字にしたが、投稿する情報は information ではなく intelligence であることを強調しておきたい。
TLのwebページでは、Search Partyを"OSINT CTF"と銘打っている。しかしこの通り、世間一般のCTFとは大きく離れた競技形式であると言ってよいだろう。
「現実の調査を模倣したゲーム」ではなく「ゲームを模倣した現実の調査」であることを理解しないままゲーム感覚で挑んだ結果、私は痛い目を見るのであった。
Search Partyのプラットフォーム

コンテストはSearch Party専用のプラットフォーム上で行われる。操作方法はTLがプラットフォーム説明動画を公開しており、その動画で網羅的されている。 本記事ではプラットフォームの説明を、重要と思われる部分に絞って行う。
- コンテスト中は4名のMPのカードが表示されている
- カードにはMPの失踪時の情報が載っているが、ほとんどは捜査機関のページから転載したもののため、source として貼られているurlの捜査機関のページを確認したほうが良い。
- カードに備わっているフォームからMPに関する intelligence を提出する。提出すべき情報は上述した通りURL, Relevance, Supporting Evidence のセットである。
- その他
- コンテストが近づくとプラットフォームが立ち上がる
- https://tracelabs.org/searchparty
- コンテスト前にユーザ登録、チーム作成などを済ませておく
- eventbrite 決済後の order number がsearch party プラットフォームのレジストレーションコードになっている
- 一般的なコンテストのプラットフォームと同様参加チームの順位を確認できる
- コンテストが近づくとプラットフォームが立ち上がる
Search Partyで選ばれるターゲットについて
- 国・州などの法執行機関はweb上でMPの情報を公開し、捜査につながる情報を求めている。
- 参考までにFBIが公開している誘拐事件の被害者 情報求むのページ:
- 日本でいうところの、交番前に貼られているポスターに近いだろうか
- そのような法執行機関が公開しているMPから各回で4名のMPが選ばれる
- あくまで肌感覚だが4名は、セグメント(国籍、年齢、性別、人種 など) がばらけるように選ばれているように見える
- 未成年(それも日本だと連日ニュースになるレベル)もMPとして扱うことがある
- ターゲットは全チームで共通している5ため、コンテスト終了後にターゲットとなったMPについてディスカッションを行うことができる。
- その他
- コンテストの最中に、MPが亡くなっていると強い確信が持てる証拠があった際に、そのMPに関するインテリジェンスの提出を打ち切ることがあった。
ルールを理解したことで、ようやくまともなプレイが可能となった。
以下からSearch Party各回へ参加した詳細について説明する。
Search Party 参加報告
ここからは参加した4回を各クォーターとして分けて説明する。
なお全部の回で私一人の参加で、チーム名は investigators_friends としている。
2024.01(1Q) 参加分
- 開催時間(日本時間): 2024 / 01 / 28 (日) 7:00〜11:00
- 運営いわくオーストラリアのプレイヤーが参加しやすい時間帯に調整したとのこと
- 事前準備としてはルールブックをしっかり読むことと、他の参加者の体験記やTipsを読んでいた。
- 参考にした文献リストはこの記事の末尾に載せている
- 目標としてまずは最下位でいいので1件の投稿を受理されることと設定した
1Qコンテスト中
- 私がやっていたこと
- スモールスタートということで、まずは得点の低い MPの友人(10pt)、MPの家族(20pt) あたりを投稿することを狙った。
- そのために、4人のMPの名前や、失踪情報ページ内で掲載されている顔画像で逆画像検索することを行っていた
- 調査過程はnotionでまとめていた
- MPの1名を名前で検索すると、その母親が Facebook上で 捜査状況の進捗や 情報を求める投稿をほとんど毎日のように動画で行っていた
- そこで、以下のように投稿を作成した(実際は英語で投稿している)
- カテゴリー: MPの家族 - URL: - 割愛 - Relevance: - MPの母親のFacebook page - Supporting Evidence: - 母親<名前>はMPが失踪後Facebookのページを立ち上げ、捜査の進捗について共有している。- すると、数分後に投稿が accept された
- 苦戦したポイント
- 4人中3人の手がかりがまったくでてこなかった
- 4hしかない中で、私1人で、4名のMPを探すのはかなり無謀だと思った
- 逆画像検索で類似の人物が出てくるが、本人かどうかの見分けがつかなかった
- 私は西洋の顔つきを見て育ってはいないため、本人か別人かを見分けることがかなり難しいと感じた。
- 動画の英語に字幕がついていないのでわからない。
- SNSなどの画像サイズは大きく、notionで貼り付けるとすぐにアップロード容量オーバになってしまった。
- 4人中3人の手がかりがまったくでてこなかった
1Qコンテスト終了後
- 結果は 最下位付近 128位 だった。惰性で参加していた頃から比べれば、1つ受理されランクインしたことは大きな進歩と言えよう。

コンテストが終わった後、臨時チャンネルでMPについての議論が盛んに行われていた。
私が一切手がかりを見つけられなかった3名のMPについても「こんな情報があった」のような形で投稿があったため、後学のために、どうやって検索したのかを聞くこととした。
◆
すると、ありがたいことに次のようなアドバイスをいただいた。ここから言えるのは、私は単純に調査する情報源や使用するツールの網羅性の不足していたと言えることである。
- 人名検索についてのアドバイス
「<MP の名> <MP の姓>」ではなく、「<MP の姓> <MP の名>」にある可能性があります。
- Google検索以外に各種snsで検索すべきというアドバイス
Facebook で関連する投稿を検索することで情報が得られました
- ヒットしそうなプロフィール名を推測し様々なSNSで検索せよというアドバイス
まずは、MPに関連付けられている可能性のあるユーザー名とプロフィールを推定し、MPのSNSでのプレゼンスがどの程度広範囲に及ぶかを特定することをお勧めします。
- 網羅的な逆画像検索をせよというアドバイス
yandexや Pimeyes (無料の検索で十分) などのすべての検索エンジンで逆画像検索を使用することを忘れないでください。
事前準備を入念に行った結果、成功体験も手に入れ、自分の課題点もわかり、幸先が良いスタートを切ったと言える。
しかし、2Qで公開情報の調査への姿勢を見つめ直す転機が訪れるのであった。
2024.04(2Q) 参加分
- 開催時間(日本時間): 2024 / 04/20(土) 24:00 〜 4/21 (日) 04:00
事前準備
目標としては、2件受理されることを目指した。
2Qコンテスト中
1Qでの学びを活かし、FacebookなどでMPの名前を調べると、2名のMPの親族(義理の姉ら)が1Qの時のようにMPの情報を求めて活動していることがわかった。
そこで1Q同様のフォーマット(URL、URLの説明、家族が捜査の進捗について共有している旨)でMPの家族カテゴリで2件のサブミットを行った。
これで目標であった2つ分の投稿がアクセプトされる
...と思っていた。
しかし2件とも投稿物が同じ理由でリジェクトされた。

前回とはコーチが異なるため、1Qとは判断基準が異なることは想定していた。
しかし、指摘文にある「コンテクスト」や「支持する情報」 がどういう意味かわからない。
棄却された理由は、おそらく家族というための根拠が弱い、見つけたFacebookのページが本当に家族のものであるかの真偽が検証ということだと思うが、わざわざ親族を偽ってMPの情報を求める活動を行う者がいるとは考えにくい、とはいえ客観的な証拠が見つからず情報の妥当性をこれ以上上げることはできなかった。
2Qコンテスト終了後
結局0ptでコンテストが終了してしまった。
結局、自分の投稿にどのような要素があれば受理されるのか、もやもやしていたので、臨時チャンネルで助言を請うことにした。
◆
すると、またもありがたいことに複数名からアドバイスをいただいた。
- 関連性の説明が足りなかったかもしれない、というアドバイス
- 単に「家族だから提出」では弱い。
- 「なぜその義理の姉の投稿が事件調査に役立つのか」(例:捜索を呼びかけている…など)を示さないとダメ。
- 家族や友人を全部提出する人もいるが、大半はケースに関係ない。だから関連性の明示が大事。
- より親族である本人の妥当性を示すための論の補強アイディア
- たとえば、義理の姉のFBに「married to …(=兄と結婚)」と明記されていることを示すなど、複数の証拠を集め、正当性を補強する
- 証拠を画像一目で見せると良い、というアドバイス
- 多すぎる証拠をコーチに提出するのも避けるべき
- 記事のスクリーンショット、FBプロフィールのスクショ、名前や写真の一致部分などを 一枚にまとめた画像 にする。
- コーチに調べさせてはいけない。プレーヤーの方で情報を整理し点をつなぎ、コーチが一目で「なるほど、これは同一人物だ」と分かるようにするのが重要。
- とはいえ「コーチをacceptするように納得させることが目的ではない」ことを心に留めておくことが大事、というアドバイス
- コーチは「審査員」ではなく「サポーター」である。参加者の提出が法執行機関に伝わるレベルになっているかをチェックし、足りない部分を指摘している。
- コーチが文脈をもう少し補うように要求した場合は法執行機関が理解できるように直そうという意味である
- すなわち、最終的な提出物は「法執行機関が読んで理解できる調査資料」という前提で書く必要がある。
- コーチは「審査員」ではなく「サポーター」である。参加者の提出が法執行機関に伝わるレベルになっているかをチェックし、足りない部分を指摘している。
アドバイスの 1, 4 は OSINT における本質的な指摘といえる。提出物は、情報の提出先(ここでは法執行機関)にとって正当に活用できる形で情報がまとまっていて初めて受理される、ということである。
すなわち1Q, 2Qで私がやってきたことは、単に発見した情報を(ゲームルールに沿って)提出しただけであり、 intelligence ではなかったことを意味する。
◆
事の問題は、探す技術や方法論というよりも、私が調査員としてのマインドセットを持っていなかったということである。すなわち、法執行機関が今後の捜査に活用するとしたらどのような情報を収集すべきかという観点が私の調査ではそもそも抜けていた。
過去を振り返れば、これまで参加してきたOSINTコンテストでは、作問者によって調査の文脈が整理されていたため、私は自然と情報探索そのものに意識を集中してしまっていた。その結果、調査に臨む際のマインドセットや、情報をどう意味づけるかといった視点が抜け落ちていた。
ところで、過去より数多の本職の分析官が世間での"OSINT"という用語の使われ方を問題視しており、 「"OSINT" と "興味深い情報を見つけること" は異なる」と注意を呼びかけている(一例は参考文献に載せた)。このような投稿を定期的に見ていたため私自身、流石に不用意に「OSINT」という言葉を使うことはなかったが、私がこのコンテストでやったことは、見つけた情報をそのまま提出しただけであり、その教えが身に滲みてはいなかったことがわかった。
◆
それでは、どのような提出ならば受理されるか。ちょうど 2Qのコンテストでコーチをされた方の体験記がでており、悪い提出物と良い提出物の例が載っていた。

左の悪い例はまさに私が提出したものに非常に類似している。
投稿が受理されるためには、右のように、自分の見つけた情報の信憑性や再現性、および捜査上どのような意味や価値を持つか、論をsupportする必要があるということである。
左の例から右の例のように情報を補強して初めて、法執行機関は捜索活動に役立てることができる(actionableな状態になる)ということを理解した。
◆
今まで多数のOSINTのコンテストに参加してきたが、初めて調査マインドセットの欠落が原因で負けた感覚である。座学では「マインドが大事」と口を酸っぱく言われていたことなのだが、実体験してようやく理解できた。
この気付きを活かすべく3Qでリベンジを目指す。
2024.08(3Q) 参加分
- 開催時間(日本時間): 2024年8月4日(日) AM 3:00 〜 AM 7:00
- 事前準備
- 2Qでコーチをされていた方の「提出物2(いい例)」を参考に、見つけた情報を intelligence にできるように文章のテンプレートをつくっておいた

intelligence提出テンプレート - 逆にこのテンプレに沿えない情報は intelligence まで持っていけないと判断し、サブミットしないようにした。
- あらかじめ OneNote に4名分のページを作っておき、貴重な時間を無駄にしないようにしておいた
- 2Qでコーチをされていた方の「提出物2(いい例)」を参考に、見つけた情報を intelligence にできるように文章のテンプレートをつくっておいた
- 目標としては、2Qで学んだことを活かし ちゃんと intelligence として投稿物を作成し、受理されることを掲げた。
3Qコンテスト中
- AM 3:00 開始ということで、かなりきつい立ち上がりであった
- 情報の調査においては1Q,2Qと同じく、逆画像検索とキーワード検索を使用した
すると1件のMPの祖母のFacebookプロフィールを発見した。
そこで私はあらかじめ準備していた提出テンプレを用い、次のような Supporting Evidence を組み、以下のように提出をした。(実際は英語で投稿している)
こちらが行方不明者の祖母のFacebookアカウントです。 • この情報は重要です。彼女がMPの情報を求めているため、この情報を起点にピボットを行い、他の関連アカウント(例えば他の親族など)も特定できる可能性があります。 • Facebookの名前検索機能を使用してこのアカウントを発見しました。 プロフィールのカバー写真が行方不明者のものと一致しているため、このアカウントが本人のものであると確信しています。証拠を画像で提出します。 (画像をアップロードし、MPの顔画像がFacebookのプロフィールのカバー写真にあることを提示)

投稿物作成時に意識したことは、今まで指摘を受けてきたマインドセット面に関することである。
- 見つけた情報は今後の捜査でどのように活用できるのか(actionableとなるのか)
- どうやってその情報を見つけたか(オープンソースにあることを証明するか)
- 情報の正当性をどう保証するか
そして、めでたく投稿が受理された。
3Qコンテスト振り返り
コンテスト終了後プラットフォームがダウンしてしまい、スコアは閲覧できないが、他のプレイヤーの投稿から、私(investigators_friends)が最下位にいることを確認した。
Just participated in my first @TraceLabs CTF with @Steven_DFS @DorianeBrt and Kchak! 🚀 We managed to finish 11th, and I'm pretty happy with the result for a first-timer. It was an intense experience, and it feels great to contribute to the search for missing person #OSINT4GOOD pic.twitter.com/TygehZUTDz
— Prox (@OsintTheWorld) 2024年8月3日
受理件数は1件にとどまったし、法執行機関も親族のSNSくらい把握しているとは思うが、自分の中では根拠立てた提出物の作成ができ、それが受理されたので嬉しかった。
3Qで提出した物は1Q,2Qと同じく親族に関するものではあるが、提出物の質には大きな質の違いがあり、このような形で改善していけたことは成長を感じる。
- 今後の課題
- 逆画像検索 結果が本人なのか そっくりさん なのかがやはり 見分けがつかない
- ここが他のプレイヤーと差が開いているポイントに感じる
- 逆画像検索 結果が本人なのか そっくりさん なのかがやはり 見分けがつかない
- 次回から
- 単純作業の軽減で時間を無駄に使わない
- メートル、ヤード、ポンドーグラム 変換器は用意しておく
- MP4人分の画像ダウンロードフォルダを作っておく
- 単純作業の軽減で時間を無駄に使わない
3Qでようやく成長軌道を乗せることができたと感じる。この調子で4Qにも挑む。
2024.11(4Q) 参加分
開催時間(日本時間): 2024年11月17日(日) AM 8:00 ~ 正午12:006
事前準備
- 調査の過程で見つけるであろうメディアをダウンロードしておくためのフォルダを4名分作っておいた
- MPに関する情報は画像だけでなく、動画で公開されていることが多く、OneNote で管理するには大変なため。
- 使うツールの用意
- あとはこれまでにやってきたことを継続することを心がけた
- 調査の過程で見つけるであろうメディアをダウンロードしておくためのフォルダを4名分作っておいた
- 目標としては、投稿を2件受理されることとした
4Qコンテスト中
- これまでと同様、4名のMPのうち3名は全く見つからなかった。しかし、残り1名のMPはFacebookに 同姓同名のアカウントが見つかった。
- これは カテゴリ "MPに関する基本情報(50pt)" が狙えると考えた。
- とはいえ、アカウントが同姓同名 であることだけでは流石に根拠に乏しく、 intelligence にはならないであろう。2Qの二の舞いになる。
- プロフィール画像も登録されていたが、加工が強くかかっている印象で、失踪情報に掲載されていた写真とは少し雰囲気が異なって見えた。そのため、この段階で同一人物と断定するのは難しいと感じた。
- そこで、ここまでの経験を思い出し、論を補強することを試みた
- 着目したのは、Facebookのフレンドリストである。MPの姓に一致するアカウントがいくつか存在する。MPの親族である可能性が高い。
- 実際にフレンドリストのアカウントは、MPについて情報を求めている。
- さらに、そのうちの数名は、捜査情報ページに載っている親戚の苗字にも一致しており、親戚もまたMPの情報を求めていた。
ここまでの情報から私が見つけたSNSアカウントは MP のものである可能性が高いと判断し、提出物作成作業に入った。
最終的には、以下のように投稿を作成した(実際は英語で投稿している)
- カテゴリー: MPに関する基本情報
- URL:
- 割愛
- Relevance:
- MP本人のFacebook page
- Supporting Evidence:
- プロフィール名がMPと一致している。
- このアカウントのフレンドリストには、MPの家族や親戚が登録されている。
- なぜ、家族あるいは親戚と判断したかの根拠については添付画像で示す
添付した画像のイメージは以下。2枚のスライドを1枚に連結して提出した。


4Qコンテスト振り返り
私の提出物は受理され、50ptを獲得した。最下位ではあるが、最高得点の更新である。


- 今後の課題
- 調査〜レポーティング の スピードが足りない
- 今回の論証スライドの作成に1hほどかかり、提出はコンテスト終了5分前となった。
- 調査(なぜその情報は重要なのか、その情報はほんものかのファクトチェック)、レポート作成までのスピードを全体的に上げる必要がある。
- 調査〜レポーティング の スピードが足りない
- 今後のアクション
- 調査の効率化
- Facebookを手繰る技術を勉強する
- レポーティングの効率化
- 文章の整形をLLMに提案してもらう
- 調査の効率化
資料作成は大変ではあったが、自分が見つけた情報の正当性を、公開情報をさらに深ぼることで補強していく作業は、調査を有機的に行っていてやりがいを感じた。
まとめ
実在の行方不明者をターゲットとしたOSINTコンテスト『Search Party』に2024年参加したことをふりかえった。
Search Partyへの参加を通じて、情報を「調べること」と「誰かが活用できる形にすること」との間には大きな差があり、私には情報をインテリジェンスへと昇華させるためのマインドセットが欠けていたことを痛感した。 そして調査では、「誰に・何の情報を・何の目的で・どう活かしてもらいたいのか」 という方針を明確にし、戦略的に公開情報を探す必要があることを学んだ。
この気づきによって、調査時に「情報の活用者の目線に立った調査とは何か」「ターゲットに関する情報をどう意味(価値)づけるか」 といった点を意識するようになり、各回の提出物だけでなくそこに至るまでの調査の質が上がったように感じる。
◆
ところで、上位帯のチームに目を向けると、7000pt以上を獲得しており、わずか4時間の中で良質なインテリジェンスを数多く生み出している。彼らの発言によると「MPの発見に重要な手がかりを見つけた」と言っている。驚くべきは、彼らは「GoogleとFacebookしか探していない」とも言っていたことである。私と彼らで同じツールを使いながらも、結果に雲泥の差があり、やはり調査は方法論よりもマインドセットが肝心なのではないかと思う。
そして、OSINTが現実の失踪事件に対する解決の糸口になっている所を見ると、OSINTの強力さ・奥の深さ・難しさ を改めて思い知らされる。精進していきたい。
◆
幸いSearch Partyは過去の参加報告記も豊富にあり、また、TLコミュニティの互助も健全に機能しているので、今後もコンテストの参加を通してOSINTベースの調査技能を養っていく場としたい。
総括すると、Search Partyは、目的を持った調査活動のためのマインドとスキルを磨く良い機会を与えてくれた。今後も継続的に参加し、いずれは上位帯のように、捜査に真に役立つインテリジェンスを提供できるようになりたい。
参考文献
記事内で参照したリンクと一部重複するが、この章で一覧としてまとめておく。
Trace Labs 公式
- HP
- Search Party ルールブック
- Search Party の説明動画
- Trace Labs OSINT Field Manual
コンテストに効果的に取り組むためのコツ、write-up
- How Cyber Pros Use OSINT To Help Find Missing Persons (Tracelabs CTF)
- GitHub - C3n7ral051nt4g3ncy/TraceLabs-Flag-Categories-Guide: This is a guide to understand Flag categories for Trace Labs OSINT Search Party CTF events
- https://github.com/C3n7ral051nt4g3ncy/TraceLabs-Flag-Categories-Guide
- 各カテゴリをどのように見つけるか、に焦点を置いた解説があり勉強になる。
- https://github.com/C3n7ral051nt4g3ncy/TraceLabs-Flag-Categories-Guide
- Trace Labs OSINT Search Party CTF — My conINT 2020 Writeup | by Wyatt Tauber | Medium
- A noob’s guide to Trace Labs Search Party CTF – osintme.com
- Trace Labs CTF August 2020 - Approach & Methodology - AaronCTI
- My Experience as an Osint Coach — TraceLabs CTF
その他
- OSINT ≠ 情報発見 に関する本職のコメントの一例
Dutch Osint Guy氏のコメント(🇷🇺🇺🇦関連でハッシュタグosintを含む投稿に関する注意喚起)
OSINF is not OSINT #OSINF = Open-Source Information and lacks context and analysis. (Finding info)#OSINT = A structured analysis methodology to collect, proces/exploit and analyze Open-Source information that addresses an Intelligence requirement (analysis of info)
— Dutch Osint Guy Nico (@dutch_osintguy) 2022年12月17日OSINTのすてきな乱れ - 切られたしっぽ
- なお、OSINT CTFチーム pinja も講習にて「マリアナ海溝並の隔たり」と喩えていた。
スポンサードリンク
- 同氏に関して2024年8月に訃報があり、Discordには同氏を偲ぶチャンネルも存在する。さすがにこのコミュニティで私がmeow_noisyという名前で活動するには誤解を招くので、nyao_noisy というハンドルで参加している↩
- コンテスト前のメール文の一説を引用する: "You'll be competing in a CTF tomorrow but don't lose sight of the mission. If you are competing tomorrow simply to put points on a scoreboard and maybe win prizes then please request a refund in Eventbrite right now. While we've gamified the intel collection process this is not a game. "↩
- 開催数日前に追加で数枚だけ補充されることがあるため、Discordのアナウンスチャンネルを見張っておくといいことがあるかもしれない。↩
- かつてはjudgeと呼ばれていたが2024年1月に正式に改称された。↩
- したがって、各チームが提出したintelligenceは、運営サイドが、法執行機関に提出する前に同じものをまとめていると考える↩
- Open xINT CTF 2024の翌日である↩
Browser Use のユーザ割り込み機能の調査

目次
記事概要
AIエージェントにブラウザを操作させるツール『Browser Use』のユーザ割り込み機能のデモと、エージェントはユーザが割り込んだ状況をどう解釈して作業を再開するのかコードを追って内部処理を調べた。結論としてはLLMの力をアテにして何とかリカバリさせている感が強かった。
背景
『Browser Use』はAIエージェントにWebブラウザを用いた作業をさせることができるpython製のツールである。
エージェントに指示内容のプロンプトを与えてスクリプトを実行すると、あとはLLMが指示内容を達成するための手順を構築しブラウザの操作を実行する。
私はもっぱらwebの調べ物をするタスクをエージェントに依頼しているが、時々私がブラウザを操作したい場面がある。
どうしたものかと思っていたが、いつの間にかエージェントのタスク実行中にユーザが割り込みしブラウザ操作できる機能が追加されていた。(関連issue: https://github.com/browser-use/browser-use/issues/221#issuecomment-2843745594)
ユーザ割り込みの方法は、エージェントがタスク実行中に、ユーザがコンソール上でCtrl + Cをキー入力すると、割り込みをかけることができ、エージェントが一時中断状態になる。ユーザがブラウザで必要な操作を行った後、コンソール上でEnterを押すとエージェントの作業を、ユーザ操作後から開始できる。
Browser Useのユーザ割り込み機能のデモ
ユーザ割り込みのデモを動画にした。
デモシナリオとしては、「meow-noisyのgithubリポジトリに秘密の情報を公開しているURLがあるのでその秘密を取得させる」というものである1。ただし当該のURLにはreCAPTCHAが設けられておりエージェントは解けないので、その部分は人間が介入して調査を進めるというものである。
※ ⚠️ reCAPTCHAの例はあくまでエージェントがタスクを実行できない例として用意したものです。Browser Use 使用時はエージェントにアクセスさせるサイトの利用規約を遵守ください。
割り込み機能の紹介は以上。以降ではどのような処理が内部で走っているかを調べる。
コード調査: ユーザ割り込み後の状況をエージェントはどのように判断しているのか
ユーザ割り込みから復帰できることがわかったので、内部的にエージェントがどのように復帰するのかを調べた。
結論としては、割り込みがかけられている間にユーザが何をしたかエージェントは把握していなかった。作業再開時、割り込みがかけられる前の文脈、および割り込みから再開された地点のURLやページ情報から、最初に設定されたタスク達成のために何をすべきかLLMに考えさせるというものだった。
参考程度にユーザ割り込みを含むBrowser Useのシーケンス図を提示する。
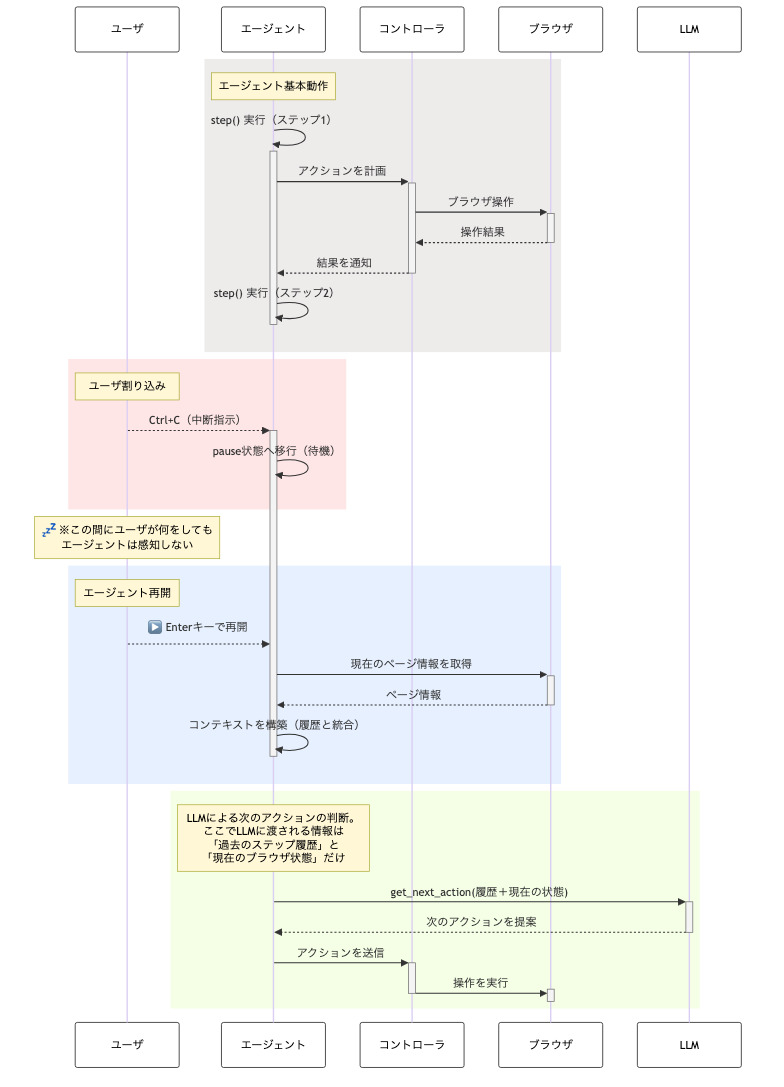
以下、過去の解説記事を参考にしつつ、コードを適宜github copilotに質問しながら処理の中身を追った過程を記す。
ただしコード調査は commit id: 726dd30c824b16b40baf6d6450da4b958e2adc4f(2025/06/21) のものなので、今の実装とは異なる点があるかもしれない
Browser Use のロジックに関する基本的事項
そもそもBrowser Useがどのように動いているのかわかっていなかったので有志の技術記事で勉強した。
※括弧付きの数字は記事末尾の参考文献の番号に対応する。
- Browser Useも基本的にはLLMにタスク達成のための作業を考えさせる処理がプロンプト含めハードコードされている[1]
- ブラウザを操作するにあたっては、おおよそ3つのコンポーネントからなっている[2]
- Agent: ユーザから依頼されたタスクをどのように達成するかを考える部分。LLMを用いてControllerが行うアクションを計画する。
- Controller: Agentが計画したアクションを実行する部分。
- Browser: playwright越しにブラウザで、Controllerの命令を実行する。
- AgentはBrowserから収集したURL、タイトル、DOM、スクリーンショット(画像)などを収集しながら、タスク達成に必要な次の作業を考える[3]。作業実行はステップという単位で管理されている。
- Agentはステップの履歴を持っており、そのステップにたどり着いた文脈や、タスク実行時のエラーが起きた記録なども持っている[1]。
ユーザ割り込みのロジック
コードを覗いてユーザ割り込みがどのように行われているか確認した。
ざっくりいうと、エージェントはforループでステップを進めるが、非同期に走っているキー入力監視プロセスが割り込みをかけエージェントの中断・再開を制御するというものだった。
- エージェント
- エージェントはrun()内で step() を呼び、LLMによる作業計画とブラウザ操作を1ステップ行う。forループでstep()を繰り返し呼び、最大でmax_steps (デフォルト50回)分を実行しようとする。
- キー入力監視プロセス
- エージェントには割り込み監視のためのSignalHandlerというクラスからオブジェクトsignal_handlerを生成し、ユーザのキー入力を非同期に監視している。
- step()実行中に、Ctrl + C キーが入力されると signal_handlerの"Ctrl + C"キー操作に結びつけられているpause()が呼び出されsignal_handlerの状態がpause状態に移行する。
- ブラウザ操作の中断
- pause状態になると同時に、asyncio.CancelledErrorが投げられstep()を抜け、また、操作履歴に、「エージェントの実行をユーザによって中断された」というメッセージを追加する
- エージェントの待機
- step()から、run()のforループ先頭に戻ってきて、pause状態のif文内に入り、Enterキーの入力待ち状態に入る。
- エージェントの再開
- pause状態中にEnterキーが押されるとsignal_handlerのpause状態が解除され、再度run()のforループが回り始める
ユーザ操作後のエージェントの再開に関して
次に、ユーザ操作後にエージェントがどのように作業を再開するかをコードベースで説明する。
とはいえ、生のコードを見ないとおそらくイメージが沸かないと思うので、「pause状態中にユーザが何をしたかの情報はなく、エージェントは再開後のブラウザの状態と過去の操作履歴だけから復帰しようとしているんだな」という雰囲気だけ掴んでいただければと思う。
大きく分けて4工程あり、
- pause状態が解除されると、再度step()を実行しブラウザ操作を計画しようとする。
- ただし、pause状態中のエージェントはキーの監視以外何の処理もしていないため、ユーザが何をしたのかは全く把握していない。
- 過去の情報と今の状況だけから次のアクションをLLMに考えてもらうべくプロンプトを組む。
- step()内でLLMへ入力するプロンプトを生成するための文脈情報の収集を行う
step内の
self._message_manager.add_state_message()で、pause後のブラウザの状態を記録している。self._message_manager.add_state_message( browser_state_summary=browser_state_summary, model_output=self.state.last_model_output, result=self.state.last_result, step_info=step_info, use_vision=self.settings.use_vision, page_filtered_actions=page_filtered_actions if page_filtered_actions else None, sensitive_data=self.sensitive_data, )与えている情報のうち重要と思われるものをピックアップ
- browser_state_summaryが再開後に取得されたブラウザの状態(どのサイトを開いているか)
- model_outputがLLMが前回どんな思考・評価・次の目標・アクションを生成したか
- result=self.state.last_result で、割り込みが起きたというエラーメッセージが入力される。
プロンプトの生成
self._message_managerに、これまでのstepにおけるメッセージの記録がたまっており、self._message_manager.get_messages()でプロンプトを発行するget_messages() では本当に過去のメッセージが連結されているだけ。
def get_messages(self) -> list[BaseMessage]: """Get current message list, potentially trimmed to max tokens""" msg = [m.message for m in self.state.history.messages] # ... return msgmessageの具体的な中身までは追えていないが、github copilotに聞くと次のようなものらしい。このうちのHumanMessageやToolMessageの中に、今のブラウザの状態やブラウジング履歴が含まれているらしい。
[ # System prompt SystemMessage(content="You are a browser agent..."), # ユーザーのタスク HumanMessage(content="Go to example.com and click the login button."), # エージェントの思考・アクション提案 AIMessage(content="", tool_calls=[...]), # ツール実行結果 ToolMessage(content="Clicked login button. Page loaded."), # ...以降、ステップごとに追加されていく ]
LLMの呼び出し
- このメッセージをLLMへの入力として、
self.get_next_action(input_messages)で LLMにアクションを生成させる。
- このメッセージをLLMへの入力として、
ここまででわかった通り、LLMに与えているのは、エージェントの過去の履歴と、割り込みからの復帰後の状態のみである。LLMは渡された情報をもとにどうすれば作業達成できるかを考えタスクを再開している。
pause状態のエージェントは人間で言えば気絶しているようなものであり、ゴールと文脈情報だけでリカバリを図るのは中々LLM頼みだな、という所感。
おわりに
Browser Useのユーザ割り込み機能について調べた。
当初は「中断された文脈がわからずにエージェントが動けるわけがない。ユーザ割り込みなんて無理だろう」と思っていたので、この機能があるのは調査を進める上でありがたい。
とはいえ、割り込みからのリカバリは中々LLM依存なところがある。
したがって、ユーザサイドもBrowser Use の仕様を理解した上で割り込み後の状態を引き継がせる工夫をする必要はあると思う。
参考文献
- [1] browser-useの中の処理をみる
- https://zenn.dev/yusukeiwaki/scraps/3c73e93497315f
- この記事で紹介されている以下の記事も参考にしています
- [2] browser-useの基礎理解
- [3] Browser Use実装解説Part2
DIVER OSINT CTF 2025 チーム内作戦会議 (Team: KAKITSUBATA)

目次
この記事について
DIVER OSINT CTF 2025 において、チームの前打ちで使用した資料です(writeupはこちら)。
2024年度の前打ち資料をベースに、2024年のCTF参加後にわかったことや競技シーンの変化(生成AIツールの普及など)も考慮してアップデートしています。
もちろん2025年CTF開始前に書いたものなので的はずれな内容も一部あることをご承知おきください。
こんなことを言うのもアレですが、最初のアイスブレイクが前打ちの主目的なので、作戦内容自体はおまけみたいなものです。
↓以降が前打ちで提示した資料です↓
アジェンダ
- マイクチェック
- 当日やると結構焦るので。
- 当日は長丁場なので、ワイヤレスイヤホンを使っている方は予備のイヤホンマイクでもテストするとよいかもしれません。
- 自己紹介
- 自分の情報を開示することは警戒されるかもしれないので最低2点だけで大丈夫です。
- HNの読み方
- 好きなオープンソースのサービスとかツールとか、分析事例とか、過去のCTFのOSINT問題とか
- +α OSINT問のここが好き、みたいなものがあれば)
- 自分の情報を開示することは警戒されるかもしれないので最低2点だけで大丈夫です。
- 当日のCTFの取り組み方(作戦)
当日のCTFの取り組み方(作戦)
基本方針
- チーム内目標
- 楽しむ!
- 勝ちにはこだわりたいですが、納得できる頑張り方ができればOKと思っているので、負けることは怖くありません。
- 楽しむ!
- CTFの取り組み方
- 基本的に好きに解き進めてもらう
- やさしい問題から順に解いてウォームアップ
- ひっかかりそうならパスして解けそうな問題を探す
- やさしい問題から順に解いてウォームアップ
- 難しい問題が残ってきた段階で、必然的に全員で叩く流れになると思います。
- 適宜チャットで力を借りたりバトンタッチする。
- 例
- 「写真が沖縄っぽいんですけど沖縄に詳しい方います?」
- 「WordPressから情報引っこ抜くっぽいですが30分探しても見つからなくて泣いた」
- 例
- 基本的に好きに解き進めてもらう
情報共有手段
- OneNote

- 問題ごとにページを割り当てる
- 空ページを10カテゴリx10ページくらい作ったのでタイトルを書き換えていただければと思います。
- 始まった直後のカテゴリの位置を定位置として、OneNoteのカテゴリ部分を記載したいです
- Dynamic形式のCTFということで、常にカテゴリとパネルの位置が動きまくることが予想されるため。
- ページタイトルは”問題名”
- 欲を言うと"問題名(難易度)"だと嬉しいです
- メモるべき情報
- 基本的に、なんでもあり
- 見つけた情報、仮説など。
- 例外として、生成aiとのチャット履歴はとても長くなるので別ページだとありがたい
- 最低限
- 問題文
- 日英両方
- サブミットしたフラグ correct / incorrect 問わず。
- geo問はマップ、緯度経度が表示されたスクショを貼る運用にしたいと思います。
- 座標のテキスト化は任意とします。AIに画像から文字起こしさせればよいです。
- geo問はマップ、緯度経度が表示されたスクショを貼る運用にしたいと思います。
- 問題文
- フラグゲットしたものは左横に✔を入れてもらえるとありがたいです
- 基本的に、なんでもあり
- ページを汚すのがためらわれるならば、調査過程を個人ページに記載して、「こっちみてください <ページURL>」でもいいと思います。
- メモ共有媒体はOneNote以外でもよいですが、リンクを知っている人以外が閲覧できないようになっているかをご注意ください(OpSec)
- もしもページの競合が発生し重複ページができたら
- コピー番号がついている方を「ゴミ箱」セクションに放り込んでください
- 備考
- デスクトップアプリ版の方が、問題をトグルできるので便利
- ただし、MSアカウントが必要になると思うので、イニシャルなど知られたくない場合は一時的なアカウントを作る必要がある
- ドラッグアンドドロップでノートの階層を移動できるようになっていました(右クリックでメニューからやる必要がなくなった)
- デスクトップアプリ版の方が、問題をトグルできるので便利
- Discordの位置付け
- 共有ドライブ(proton drive, onedrive)
- ノートには貼り付けられないような容量のファイル(動画など)を共有するためにご利用ください
- フラグフォーマッタ
- 簡易webサイトをデプロイしました
- kuzushikiさんが開発したフラグフォーマッタ ブックマークレット 1
- https://gist.github.com/kuzushiki/8016328857867d7d1a25851e77e721d6
- CTFdパネルのフォームにテキストを入力してブックマークレットを叩くと指定フォーマットへ加工してくれる。
- 例えば
xxxと入力するとDiver25{xxx}に置換してくれる。
- 例えば
- また、webhook連携すると、discordで通知もしてくれる。

- CTFdパネルのフォームにテキストを入力してブックマークレットを叩くと指定フォーマットへ加工してくれる。
- https://gist.github.com/kuzushiki/8016328857867d7d1a25851e77e721d6
- 使用義務はありませんが、フラグ整形ミスにご注意ください
- やってもらえるとありがたいこと
- フラグゲット報告 (士気アップにとても重要!)
- 自分が解いている問題のページの先頭に、自分のアイコンを駒として置く。例↓

- 口頭でいうよりも楽で、解く問題が被ってしまうことは少なくなるはず。
- 各人のアイコンは 「基本情報 > アイコン」 ページに置いています。

出題される問題について
- 難易度(2024年度): introduction, easy, medium, hard
- 全完されないつもりで作っているとのこと
- 2024年は上位チームでも枠に余裕があったことや、2位のチームは半日残して残りmapper 1問だけになっていたことを考えると、今年はeasy, medium, hardが1ランク上になる可能性がある。
- ジャンル
Cyber Kill ChainのReconnaissanceとしてのOSINT、ジャーナリズム・ファクトチェックのためのOSINTなど、様々な面から実世界でのOSINTを意識した問題を出題する予定です - https://x.com/geo_vitya/status/1777282885399277746 より
- 何問くらい出る?
- 2024年: 35問
- (DIVERチームは 量よりも質を重視しているように見えるため今年も同じ量か、それ以下になるのではないかと思っています
- 2024年: 35問
- どんな質の問題が出る?
- 2024年に参加した印象だと基本的には、お題を分析し、仮説などをもちながら、Web検索でソースを見つけていくものが多かった。
- とはいえ公式write-upに書かれているような直線的な調査にはならず、ノイズ情報に引っかかりながらチーム総力を挙げてフラグを見つける形であった。
- また、知識がなくても解けるというよりは、CTFの中で調査ドメインの勉強をしながら、調査していく感じ。
- 2024年に参加した印象だと基本的には、お題を分析し、仮説などをもちながら、Web検索でソースを見つけていくものが多かった。
- ルールより: “一部の画像などは競技上の理由により、競技時間中は出典が伏せられるものがあります”
- → 手持ちの写真以外から写真問題を作るスキームの確立。
- 日本国外の問題を増やせる
- 公式writeupより
可能な限り国際的にする(中略)次回以降はさらに「平等な言語バリア」の取り組みを加速できればと考えています。
- → 手持ちの写真以外から写真問題を作るスキームの確立。
- ルールより: “本競技では、模擬的な偽情報を含む可能性があります。”
- → ファクトチェック問題が出る可能性
- 記述式問題(レポート)
- 不明点を運営に問い合わせ
- medium以下の難易度も解く必要がある? → No, mediumのみ
- CTF開始時点で問題は閲覧できる? → No, medium全部解いたら出現
- (pdfにまとめる形で渡したいのだが)回答フォームにテキストで書かないといけない? → No, チケット部屋でファイル提出など可能。
- 不明点を運営に問い合わせ
調査にあたってのtips
調査の基本的tips
- 「妥当な手順や方向で調査をしているのに、ターゲットが見つからない」という例の状態 が起きたら
- 生成AI の出力結果に気をつける。
- LLMは確率的に言葉を生成している(事実に基づいているとは限らない)
- 四則演算やbase64デコードなど、ロジックで処理できるものは、AIに任せないほうがいいです
- 昔あった例
- base64デコードで1文字異なることがありました。
- 表形式の画像を与えて合計を計算させるというタスクでも計算ミスが起こりました
- PDFなどのドキュメントを説明させることを依頼した時も、全く書かれていない内容を生成したこともあります。
- 経験上ページ数が多いほどその傾向が強いと感じます。
- 過去に観測した たちの悪いものとして、架空の出典をでっち上げるケースがありました。
- 昔あった例
- 生成AI検索も、バックエンドで使う検索エンジンに縛られます
- 生成物の検証は必ずお願いします。
- トータルとして生成物の真偽検証プロセスは避けられず、調査の時間短縮を目指して生成AIに頼るのは逆効果になる可能性があります
- 機械翻訳結果の解釈にも気をつける
- 昔「unique」を「ユニーク」を「奇抜な」という意味で捉えてしまったために嵌まってしまいました…
- 調査で頭が疲れてきたら
- 散歩
- 雑談
- ミームづくり
- …など。

運営への問い合わせ(ゴネ)のtips
- 別解やフラグ設定ミスの可能性がある以上、ゴネはやるべき。ただし手順とマナーは守る。
- ゴネには3つの要素が基本的に必要
- 不正解だったフラグ、そのフラグをどう取得したか、そのフラグが題意を満たしていること
- write-upを書くようなもの
- 不正解だったフラグ、そのフラグをどう取得したか、そのフラグが題意を満たしていること
- まず挨拶でCTFを開催してくれたことに感謝と敬意を示しつつ、運営に3つの要素に提出し、「これは本当にincorrectなのでしょうか」と (気持ち下から) 確認をお願いする
- 生成AIは使わないほうがいい。機械を使うと機械的に対応される。
- 運営も人間。
- 生成AIは使わないほうがいい。機械を使うと機械的に対応される。
- 大体は「問題をよく見て」とあしらわれるが、ゴネが成功すると正解の部分的な断片が回答に含まれていたり、調査方針の正当性の担保ができたりする
- 例: 曲名を当てる問題で
- 私「グーグルの音楽検索って使ったりする? 私の国からだとそのサービス使えないんだけど」 → 運営「日本から解けることを確認した」
- → グーグルの音楽検索 が キーになりそうと確信。
- 私「グーグルの音楽検索って使ったりする? 私の国からだとそのサービス使えないんだけど」 → 運営「日本から解けることを確認した」
- 例: 曲名を当てる問題で
- 最後、お礼を言ってチケットをクローズする
健康面tips
- 健康
- 休憩や睡眠
- 各自がパフォーマンス出せるように取り組んでいただければと思います。
- meow_noisyはトータル2hくらいは休憩、その他 00:00〜6:00仮眠予定です。
- 各自がパフォーマンス出せるように取り組んでいただければと思います。
- 1問も解けなくても気にしない!
半分自分対する言葉ですが- 「探したけど情報が見つからなかった」という結果も調査においては価値があります。
- 調査いただけることが最大の貢献です^^
- 休憩や睡眠
- 調査時のメンタルヘルス; 代理トラウマ(Vicarious Trauma) への対策
- Diver運営が紹介したbellingcatの記事も良いのですが、Dutch Osint Guy氏の記事↓の方が箇条書きでまとまっていて見やすいと思います
- Vicarious trauma & OSINT - A practical guide
- 特に記事内の以下のことは大事だと思います
DO NOT ever act tough! Be human! Say when something is enough or has too much of an impact on you. It’s ok to show emotions when confronted with traumatic incidents.
- [機械翻訳]決して強がってはいけません!人間らしく!もう十分だと思った時や、あまりにも衝撃が大きすぎる時は、はっきりと伝えましょう。トラウマ的な出来事に直面した時は、感情を表に出しても大丈夫です。
- どのようなターゲットが出題されるかわからない以上、meow_noisyはコンテンツが調査者の精神に影響を与えるリスクを軽視していません。
- 問題文や調査内容とCTF時の精神状態から 進む/離れる をご判断ください。
- その結果 誰も手出ししなかった、は調査のプロセスの結果として受け入れます。
- Diver運営が紹介したbellingcatの記事も良いのですが、Dutch Osint Guy氏の記事↓の方が箇条書きでまとまっていて見やすいと思います
チーム内意思決定について
- サブミット回数制限のない問題のサブミット
- 不正解によるペナルティについて (”About Flag”ページより)
"全ての問題は、ブルートフォースを防ぐため、不正解によるペナルティが設定されています。誤った提出を行うたびに、その問題は 15 分間再提出ができなくなります。 ペナルティに関わる誤答は個人単位ではなく、チーム単位でカウントされることに注意してください。ただし、最初の 3 回まではペナルティが適用されません。"
- → 3回incorrectすることは気にしていません。15分くらい、incorrectだった理由の調査や別の問題への切り替えでどうとでも過ごせます。
- このペナルティは、プレイヤーのラフプレー(調査で見つけたものや、AIエージェントに見つけさせたものを、当てずっぽうでバンバン投げるプレイング)対策で設けられたものだと思っています。皆様はこのようなプレーはしないと思ってます。気になさらずsubmitしてください。
- 5回ミスったら即終了のFrのコンテストに比べればこのペナルティは在って無いようなものです
- (正直 1h 4回投げられるならば、24hで理論上95回投げられるので、総当たりも否定しません。)
- 不正解によるペナルティについて (”About Flag”ページより)
- サブミット回数制限のある問題のサブミット
- 回数がズレる現象があるらしいので注意。 cf. “About Flag”ページより。
なお、試行回数制限と不正解によるペナルティは同時に適用されます。試行回数制限がある問題において、ペナルティによって Flag の送信ができなかった場合、解答可能な回数は減りません。しかし、CTFd の仕様上、Web ページ上では回数が 1 回減ったような表示になってしまいます(システム内では実際には減っていません)。気になる場合、再送信する前に Web ページをリロードするか、問題を開き直してください。
- (大前提: 提出しようとするフラグのフォーマットがあっていることや空白スペースが含まれていないことを確認する)
- サブミットの余裕 残り 5回以上 ならば
- → 好きにサブミットしてもらう
- サブミットの余裕 残り 4回 ならば
- → 正解の確信度 8割くらいだったら 1人の判断でサブミット
- サブミットの余裕 残り 3回 ならば
- → 正解の候補について2人以上で吟味し、正解の確信度 8割くらいだったらサブミット
- サブミットの余裕 残り 2回 ならば
- → 正解の候補について4人以上で吟味し、正解の確信度 8割くらいだったらサブミット
- サブミットの余裕 残り 1回(ラス1) ならば
- → CTF終了直前までギリギリ調査して 正解の候補についてチーム全員で吟味した上で、天に祈ってサブミット
- 回数がズレる現象があるらしいので注意。 cf. “About Flag”ページより。
- ポイント消費型のヒントが出たら の意思決定(皆様にもお伺い)
- (多分出ない気がしますが)
- どうする?3
- 問答無用で開く
- 絶対に開かない
- 状況に応じて
- ヒント開けたチームのうち正解できているチームの割合を見てから判断など
- HEXA v3のようなファクトチェック問題※があったら
- ※ 5つの記事内容を事実/虚偽 判断するもの。持ち弾は2発みたいな問題
- メンバーで同時にチャット欄に A/F をスポイラーをつけて投稿し、多数決を行う。
- 割れた部分を議論した上で、天に祈ってサブミット
- イメージ

記述式問題
- 架空のターゲットの 意図 を推測するみたいな感じ?
- 方針: なるべく情報提示しながら詳しく書く
- 文書構造
- 先に結論
- 組織
- メンバー
- SNSアカウント
- 何をしようとしていたか
- OneNoteのページをpdfに焼いて提出する
- 進め方: まずは頑張って、medium完答する
- その後、1時間コアタイムを設けて チームで話して 調査して ページに情報にまとめ 提出する。
皆様へのご依頼
- ご依頼
- ご自身のツールのメンテをお願いします
- 例
- 調査用アカウントが凍結されていないかの確認
- 調査ツールがまだ使えるかの確認
- 例
- 体調に気をつける
- 最近は気象は荒れやすく、寒暖差も激しいです
- ご自身のツールのメンテをお願いします
その他
- 課金プレイのための予算
- 15万円まで積み立てています
- 生成AIサービスなど、有料サービスを契約されたい方は支給しますのでご連絡ください。
- お金の力で解決できる所は惜しまないです。トップ・ギアを入れて参りましょう👊
- 15万円まで積み立てています
- 各人の都合を優先ください
- 当日に身体の具合が悪くなったり、緊急を要することが起きるかもしれません。また、ご家族の事情などあると思います。遠慮なく抜けていただいて大丈夫です。
- 当日meow_noisyは 11:30くらいにはボイスチャンネルにいます。
おまけ: 出題予想
xryuseixさんのCTF開催に"アホほどお金かか"ったという投稿を受けてどんな問題にお金を使ったかを予想。
ChatGPTによる逆画像検索クエリのチューニング: 夜→昼の画像変換

目次
記事概要
2025年3月末に話題となったChatGPTの画像編集技術を用いて写真を加工し、逆画像検索結果の改善を試みた結果について報告する。
背景
我々が画像についてインターネットで調査する時は、検索エンジンの「画像で検索」を主に用いる。「画像で検索」は、画像についてテキストではなく画像を入力することから、界隈によっては”逆画像検索(Reverse Image Search; RIS)”とも呼ばれる。Googleレンズが代表的なツールであろう。
この逆画像検索は、クエリとなる画像を入力するだけで、画像に類似ないし関連するwebページを探すことができるため便利1な技術である。
逆画像検索はそのまま使っても優秀だが、クエリ画像に加工を行って逆画像検索にかけることで探している情報の検索空間を広げ、より多くのページをヒットさせたり、そのままでは見つからないものを見つけやすくするテクニックが存在する。
画像の加工技術は、モザイクや反転のような決定的なロジックに基づくものの他、ウォーターマーク除去のようないわゆるAI技術(データに基づいて情報を予測する技術)が用いられる。ご興味があれば私が過去にテクニックを収集した資料を参照いただければ幸いである。
私はチューニングテクニックの収集だけでなく、自分でもチューニングの試行錯誤を行っている。本稿ではその取り組みの1つについて共有する。
夜→昼変換のお題
私が2022年頃にやろうとして頓挫したアイディアの1つに「夜の屋外で撮影された写真を昼に変換する」というものがあった。
安直なアイディアだが、場所によっては夜よりも昼の方が撮影されやすい所があるので、webページがヒットしやすくなるのではないかと考えた。
そのアイディアを試すべく次の写真をお題とした。

この写真としては、桜や紅葉の名所である弘前公園内にある「緑の相談所」という場所である。夜にライトアップされた紅葉を見に行った時に撮った写真で、施設自体はたまたま写っていた場所である。
撮った写真をそのままGoogleレンズにかけた結果が以下。
一応、候補は右列一番下の1件だけ出てくる。

この夜の写真を昼の画像に変換することで検索結果の改善を試みた。
過去に実施した夜→昼変換AIでの取り組み
2022年頃に使った画像加工技術は、画像変換(image-to-image; im2im)タスクを行うAIである。画像変換タスクとは画像に含まれるコンテンツ(何が描かれているか;what)を維持したままスタイル(どのように描かれているか;how)を変換するというものである。これをAIの力で行う。写真をゴッホ風に変換したり、馬をシマウマのような縞柄にする例を見たことがある方もいるのではないかと思う。
AI(MLモデル)の実装としては AU-GAN、 ToDayGAN がある。いずれも事前学習済みの重みファイルを公開しているため手元ですぐに夜→昼変換が可能である。
ToDayGANで画像変換を試みた結果がこちら。fake_0が変換後の画像である。

かなり元の画像を破壊している事がわかる。
fake_0の画像を一応Googleレンズで検索した結果がこちら。まったくヒットしていないことがわかる。

うまくいかなかった原因は、AIのもともとの学習データがドラレコから撮影した夜と昼の画像なので、ドラレコで撮られやすい道路などのテクスチャーに変換しようとしているのではないかと考えている。
余談だが、私は昔、写真をアニメ風にするAIの学習を試みていたことがある。結果としては、上述の夜→昼変換結果同様に、あまり芳しくない結果に終わった。このような経験から夜→昼の結果がズタズタになることはある程度予想がついていたし、「まぁ、こんな変換性能だよね」という納得もしていた。
{kind=link}
ChatGPTによる夜→昼変換AIでの実施結果
試みの失敗から数年経った今年3月に、ChatGPTに画像変換機能が搭載された。「写真をジブリ映画のキャラクターのように変換してくれる」という話題でバズったため多くの方がご存知であろう。
(参考): ChatGPT新機能でスタジオジブリ風のイラストがネットに氾濫 | ギズモード・ジャパン
手持ちの顔写真でアニメ風変換をやってみて驚いた。巷で言われているように、元のコンテンツを保持しながら画風を変換してくれる。
また、コンテンツ情報も違和感なく追加、除去、変更などがプロンプトで操作可能ということも確かめた。
夜→昼変換(秋シーズン)
とんでもない技術の進歩スピードに脱帽しつつ、リベンジということで、緑の相談所の写真に対しChatGPTで昼→夜変換を実行した。
やり方は簡単で、ChatGPTに写真と次のプロンプトを流すだけで、画像を生成してくれる。
これは夜に撮った写真ですが、昼に撮ったかのように加工できますか
変換結果が下記。拡大すると生成AI特有のセミリアルさは否めないのだが、うまく昼の風景へ変換できているのではないかと思う。

期待を込めて変換後の画像をGoogleレンズにかけたが、ヒットしなかった。

夜→昼変換(春シーズン)
次に、弘前公園は桜の名所でもあるため、桜の満開の風景に変換するとどうかを試した。
同じ対話履歴内ならば、もう一回元画像をアップロードする必要はなく、次のプロンプトを与えるだけで桜の満開の画像を生成してくれる。
桜が満開の状態にできますか。
生成した画像は次の通り。こちらもうまく変換できているように見える。

しかし、こちらもGoogleレンズでヒットしなかった。

夜→昼変換(冬シーズン)
最後、冬を想定して、葉がすべて落ちている状態だとどうなるか。
プロンプトは以下
冬をイメージして、葉っぱや花がすべてなくなっている状態にできますか
生成された画像は以下の通り。プロンプト通りに生成され毎度驚かされる。

Googleレンズの結果は以下の通り。検索が改善した。上位4件、緑の相談所のページが出てくるようになった

ChatGPTによる手法の考察
紅葉、桜ではヒットしなかったことから、紅葉、桜が却ってノイズになってしまった可能性がある。すなわち、建物を見て判断すべきところを、Googleレンズは桜の景色感で探そうとしたのではないかと考えられる。
弘前公園というスケールで見るならば、紅葉や桜の写真の方が多く撮影されているだろうが、緑の相談所という場所自体は、別に紅葉や桜の文脈である必要がない。したがって、冬の景観がうまくいったというよりも、建物だけが被写体になった昼の画像に変換できたことでwebページのヒット数が増えたのだと考える。
まとめ
- 逆画像検索の結果改善のためのクエリ画像のチューニングというテーマで、夜→昼変換を扱った。
- 手元の写真に対する夜→昼変換の実験
- ChatGPTによる夜→昼変換は驚くほど自然なクオリティで実現でき、検索結果の改善もできた。
- しかし、指定するプロンプトによってはうまく機能しない。
- どのような文脈で写真が掲載されていそうかを推測した上で画像を加工することが大事であると改めて実感した。
- トータルで考えると、ChatGPTでいろいろと文脈を変えて画像変換し、逆画像検索をすることには効果的だと考える。
rvctf2023復習: Wayback Machineの総当たり

目次
- 概要
- 問題の内容
- 問題の難しさ
- 問題の想定解法
- Wayback Machineのアーカイブ閲覧の効率化を考える
- RAGベースの文書検索で総当たりを効率化できないか
- RAGベースの文書検索の考察
- まとめ
- 参考文献
概要
2023年の DEF CON 31にて行われた Recon Village CTF(以下rvctf)で出題された問題の復習を今更ながら行う。復習というよりも別解探しというべきかもしれない。
具体的にはWayback Machineのページをいかに手番を抑えて総当たりするかを考える。最近のLLMベースの手段で解けないかも試験した。
問題の内容
“Challenge 1”1という問題名のものであり。第1問目、一番配点が低いパネルである。
問題文は以下。
We are hexapps. We build apps for others. We are quite new and do not have an old footprint. Visit our website for more info: https://hexapps.xyz
機械翻訳:
私たちはhexappsです。他人のためにアプリを作っています。我々は非常に新しく、古いフットプリントを持っていません。詳しくはウェブサイトをご覧ください: https://hexapps.xyz
問題文中のURLのページからフラグを探す問題である。
問題文に何がフラグになるのかは書かれていないものの、CTFのOSINTカテゴリを解いたことがあるプレイヤーならば、インターネットアーカイブにアタリをつけるのではないかと思う。
しかし、私が所属していたチームはこの問題を解けなかったし、記憶が正しければ140チーム以上が参加したにもかかわらずsolveが5or6程度しかなかったと思う。
それにはこの問題独特のヒネりがあるためだと考える。
問題の難しさ
実際正解となるフラグもWayback Machine内に存在した。
https://web.archive.org/web/20230805070205/https://hexapps.xyz/index.html

しかし、フラグの格納場所が恐ろしく見つかりづらい場所に設置されている。
具体的には、”https://hexapps.xyz/”のアーカイブではなく、”https://hexapps.xyz/index.html” のアーカイブの方に存在した。index.htmlの有無で別々にアーカイブがとられるようだ。
URLエントリーリストを見ると、index.htmlなし(フラグなし)のアーカイブはリストの一番上であるのに対し、index.htmlあり(フラグあり)のアーカイブは、URL下の88エントリーある内の後ろから2番めにあり、総当たりしなければ見つからないような隠され方がされている。

私は88エントリ全部見る根性は無く、「実はwayback machineではないんではないか。gitなどで別の手段でアーカイブされたものを見るんじゃないか」という風に探索空間を広げてしまい、綺麗にラビットホールに嵌まってしまった。
問題の想定解法
ここで運営から提供されるポイント消費で得られるヒントを紹介する。 CTFの時間が経つに連れ3つ追加された2。
hint1
Go back in time. Spot the difference.
機械翻訳:
過去に戻って、違いを見つけてください。
hint2:
We are not old, it should not take too much time going back in time looking for us.
機械翻訳:
私たちは古くないので、過去に戻って私たちを探すのにそれほど時間はかからないはずです。
hint3:
Been to Wayback machine? Did you see something different on the website. Check the whole page.
機械翻訳:
Wayback Machine にアクセスしましたか? ウェブサイトで何か違うものを見つけましたか? ページ全体を確認してください。
ヒントを伺うに、「Wayback Machineのアーカイブを全部見る」ことがこの問題の想定解と解釈できる。地獄ですね、、、3
一応、「総当たりしなくても効率的に見つけられるのでは」という指摘について回答しておく。
- Q1. HTMLファイルだけに絞って見ればよいのでは?
- Q2. フラグの文字列を正規表現などで検索すればすぐわかるのではないか?
- A2. 必ずしもフォーマットで加工されているわけではない。rvctf2022の時もリート表記で人目ではフラグだとわかるもののテキスト検索ではヒットしない。
すなわち、rvctfのWebページ調査問題は、経験則的あるいは機械的にフラグを取得することが非常に難しく、言ってしまえば根性を試すような要素があるということである。
プレイヤーが最初に取り掛かるであろう第1問目にこれを出題した意図は色々と勘繰りたくなるが、この問題から学ぶところを見出すとすれば、index.html を明示的に指定した方のURLのアーカイブにはまだ見ぬ情報が残っているかもしれないということであろう。
この問題1つに7時間以上突っ込んだ身からすれば良い勉強代である。
Wayback Machineのアーカイブ閲覧の効率化を考える
さて、Wayback Machineのページをすべて見ればおそらく解けた問題であるが、それを行使できなかった背景にはWayback MachineのアーカイブをWebブラウザで確認することは手間なことにある。
アーカイブ1つ1つのファイルを確認するには次の工程で行う。
- URLエントリーリスト からファイル名のクリック
- カレンダーUIから日付をクリック
- その日付のhh:mm:ssをクリック
- ページが表示されるので見る
- (+αでソースの表示)
日付のパネルを逐一確認するのは面倒だし、アーカイブが完全に表示されるまでには時間がかかり、調査のオペミスも生じやすい。
(実際に https://web.archive.org/web//https://hexapps.xyz/ で1つほど試してみるとその負担を実感できるかもしれない。)
したがって、以下のことが可能になれば、この問題はもう少し労力を減らし、かつフラグを見つけられたのではないかと考える。
- 工程1: Wayback Machine の指定したURLのリソースをすべて、かつ全時刻分ダウンロードする
- 工程2: ダウンロードしたリソースをすべて目視で確認する
工程1の実施方法は割愛するが、ツールが見つかるかもしれない。
工程1で、1つのディレクトリ内に全タイムスタンプのファイルを用意したイメージがこちら。

これで、ローカル上で効率よくファイルを確認することができるようになった。
あとは工程2として、vscodeでペインを分け、ソースを左、ビューアーを右などにすることで、webブラウザ越しの総当たりよりも手間と時間が軽減できる。
この時、画像ファイルは別ディレクトリに分けて別にすると確認がなお捗る。
RAGベースの文書検索で総当たりを効率化できないか
アーカイブされたファイルを1つ1つ見ていけばいずれ答えにたどり着けることはわかったが、いくらリソース参照のステップを時短しても、工程2の目視総当たり確認することには変わりがない。これを効率化できないかを考えた。
そこで近年のトレンド技術、RAGベースの文書検索を用いて、LLMにキーワードを含むファイルを見つけてもらうことを検討した。

RAG(Retrieval Augmented Generation;検索拡張生成)とはLLMに問い合わせる時、プロンプトに文書などのコンテキスト情報をセットで与えることでコンテキストを踏まえた回答をさせる技術である。
新しい情報やプライベートな情報など、LLMが学習したデータ以外の情報を踏まえて回答を行うbotを作成したい時に有効な手段となりうる。
特に文書検索への応用がさかん4であり、自然文で文書を検索するためのコア技術として期待されている。
自前でRAGベースの文書検索環境を組むのは多少手間がかかるので、何かいい方法がないかと思い私が目をつけたのがGithub Copilotである。
文書検索をさせることはGithub Copilotのユースケースから外れるだろうが、copilot自体はコードを理解することにチューニングされていると考えられるし、ちょうどダウンロードしたアーカイブをvscodeで閲覧していたこともあるし、最近は無期限の無料枠もあり始める敷居が低いことも後押しした。
やったことは、アーカイブを保存したディレクトリをワークスペースのルートになるようにした上で、ワークスペース全体を参照するようにして(メンション@workspaceをつけて)質問を投げるだけである。モデルはgpt4oを使用した。
問い合わせ文はこちら
@workspace I am participating in the CTF. There seems to be a hidden keyword in files in this folder. Can you help me find it?
結果はこちら、

駄目な模様。gpt4oも匙を投げてしまう。
一応、明示的に「探したいものはクーポンだ」と情報を与えた状態だとヒットする。

次に、検索範囲をvscode上で現在アクティブなペインに絞って、同様の質問をする。フラグを含むhtmlファイルに絞って同様の質問をした結果がこちら。

フラグを提案してくれた。
したがって、ファイルを一つ一つ開いて問い合わせれば、見つけてくれる期待はできることがわかった。
結局ファイルを開いて1つ1つ質問をするという総当たりの手間は省けていないが、前向きに評価するならば目視チェックしてくれる作業者が1人増えたと捉えれば良いだろう。
RAGベースの文書検索の考察
今回の問題には貢献しない結果ではあったが、個人的に、「公開情報をローカルにダンプ→RAGベースで文書検索」は化けそうな匂いがする。
今回は問題文が曖昧なために漠然としたプロンプトを与えてしまったが、例えば、氏名やユーザ名など、抽出したい情報を明示的に指定できれば機能するのではないかと思っている。これらは電話番号のように正規表現などでパターンを組むことができず知的なプロセスで抽出する必要があり、そこにLLMが役立つはずである。
また、CTFに限らず今後も膨大なオープンソースの文書を漁る場面に出くわすはずで、その時に適用できればいいと考える。
この手法が機能する場が現れることを期待して、調査手段の引き出しの1つとして持っておきたい。
まとめ
本記事では、DEF CON 31のRecon Village CTFの問題を振り返り、以下の点について検討した:
- Wayback Machineのアーカイブを効率的に調査する方法
- ダウンロードしたアーカイブの整理と確認の効率化
- Github CopilotをRAGベースの文書検索システムと見立てた場合の調査の可能性
結論として:
- アーカイブの一括ダウンロードとローカルでの確認により、作業効率を改善できる
- RAGベースの検索は今回の問題には直接的な効果は限定的だったが、明確な検索対象がある実際の調査では有用な可能性がある
- 調査手法の1つとして、RAGベースの文書検索は今後の活用が期待できる
技術が発展してもなお、調査において根性を試される場面は残念ながら無くなっていない。昔、海外のosint関係のフォーラムで「best toolは何か」というトピックに"brute force"というレスがついていたのを見かけたが、ネタではなくガチの意見だったのかもしれない。
参考文献
- rvctf 2023 2位のチームのwrite-up(現在閲覧できない)
- RAG(Retrieval-Augmented Generation:検索拡張生成)とは?:AI・機械学習の用語辞典 - @IT
- 書籍「LangChainとLangGraphによるRAG・AIエージェント[実践]入門」
- rvctf2023は問題名が基本”Challenge <#>”という形式のナンバリングで、問題名からは内容が推察できない形となっている。↩
- 私のチームはヒントを閲覧していない。CTF終了後にヒントが閲覧可能な状態となっていたものをメモしていた。↩
- しかもヒントは3つとも同じことが書いてあるに等しい。このヒント3つをポイントを払って掴まされたチームは気の毒だと思う。余談だが、私が所属していたチームはヒント開示のためにポイントを消費することが敗因につながると知っており、絶対に見ないようにしていた(参考)。rvctfの戦い方を弁えている様を見て「長年やり慣れている、というか、やられ慣れているなぁ」と内心笑っていたものである。↩
- AI関連の展示会に行くと半数近くのブースがRAGベースの文書管理・検索ソリューションを宣伝している。↩
OpenStreetMapに未登録の地物とOverpass APIを組み合わせてgeolocationする

目次
※本記事の括弧付きの数字は参考文献の番号に対応する。
概要
本記事では、overpass turboを使って写真の撮影場所の特定(geolocation)を行う場面で、探したい地物がOpenStreetMapに登録されていない場合に悪あがきする方法を述べる。
手法は真剣な試行錯誤の末に思いついたものだが、最終的にoverpass turboは使わず何だかんだ手間はかかりラフプレー感は否めないのでギャグ回だと思って読んでいただければ幸いである。
overpass turboの予備説明
overpass turboの説明のためには関連の概念も併せて説明する必要がある。自分の理解では以下の通り。
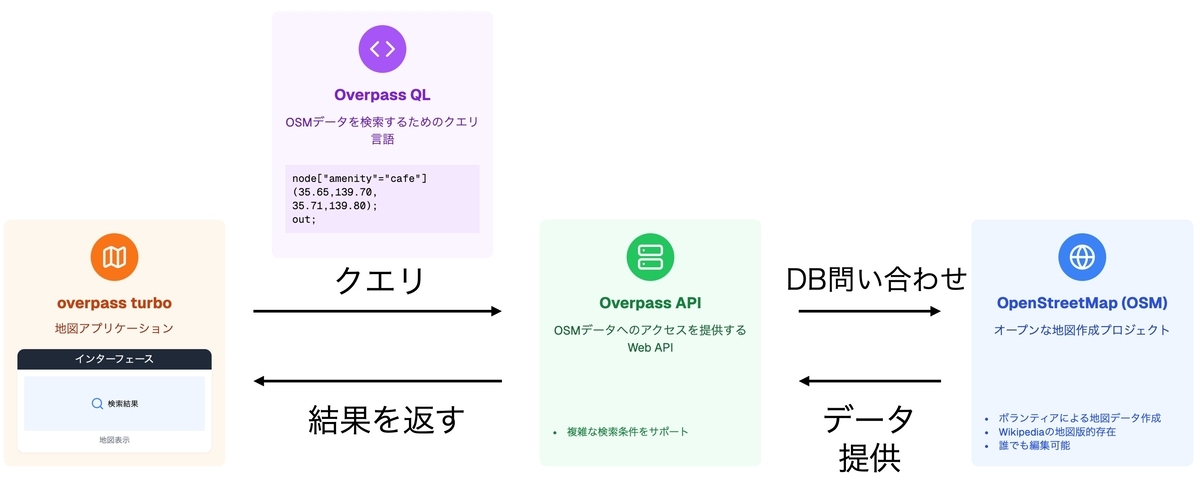
- overpass turbo: Overpass APIを用いた地図アプリ。Overpass QLで書かれたクエリを送信すると、問い合わせた結果を地図上に表示してくれる。
- Overpass QL: OSMのデータベースへ問い合わせるためのクエリ言語の一つ
- Overpass API: OSMのデータベースへ問い合わせるためのWeb API。受け付けるクエリ形式の1つにOverpass QL形式がある。
- OpenStreetMap(以下OSM): オープンな地図作成プロジェクト、また、その地図サイト。Wikipediaの地図板的存在。
よって、overpass turboは、OSMに登録されている地物を(条件をつけて)探す手段の1つというわけである。
overpass turbo自体の使い方は他のwebページで解説されているのでここでは割愛するが、overpass turboの使い方よりも、Overpass QLの文法をOverpass QL公式ドキュメントで調べたり、OSM上で地物がどのようにタグ付けされているかの用例を調べることが重要だと思う 1、 2。
本記事ではoverpass turboをgeolocationタスクに適用するという文脈における課題と解決案を提示する。
背景
2024年頃から、geolocationを行う際にoverpass turboを用いる解説記事を見かけるようになった[1][2][3][4]。
これは写真内で映り込んだ地物の組み合わせでクエリを作りoverpass turboにかけることで、地物が地理空間で隣接する場所を絞れることがgeolocationを行う上で非常に有効であるという認識が地理空間を扱う分析官の間で広まったためだと考える。
紹介した4つの文献は海外の技術記事であるが、国内の写真でも有効であることを確認している。
例えば、こちらの写真に対するgeolocationを行う際のoverpass turbo適用する例を示す。

(画像出典: DIVER OSINT CTF 2024 『246』)
これはどこかの県の県道246号付近と遠くに見える橋を手がかりにgeolocationすることを想定したOSINT CTFの問題だが、県道246号に隣接する橋をoverpass turboで検索したときのクエリと実行結果を示す。

どのあたりを重点的に調べればよいかがわかる。
このように、写真内の地物を洗い出しそれをoverpass turboで検索できる形でクエリを形成することにより、調査の時間を短縮できる可能性がある。
ちなみにgeolocationの技能を問う問題が多数出題されるOSINT CTFの界隈でも、2023年頃からoverpass turboを使用するプレイヤーが現れ出し、問題自体もoverpass turboの使用を想定解法にするものが出るようになった[5]。
以上を踏まえると、geolocationをする上でoverpass turboは逆画像検索に並ぶ必須テクニックになったと言える。
overpass turboの課題
しかし、overpass turboを適用するためには、大前提としてOSMに地物が登録されている必要がある。
一方で、写真内に写っているものが全てOSMに登録されているわけではない。たとえば、OSMは公共物などはカバーされているが、店舗のような流動性が高いものは登録されていない場合もある。地物の登録は有志のマッパーの貢献があってこそのため、overpass turboで何でもヒットするわけではない。
とはいえ、一部の地物がOSMに登録されていないからといってoverpass turboの強力なAND検索機能を断念するのはもったいないと思い、悪あがきを試みることとした。
先に方法の概略を述べると、overpass turboで一気通貫しようとするのではなく、バックエンドのOverpass APIをベースに使いつつも、Overpass APIだけでは実現が難しい部分を別途プログラムを書くアイディアである。
本記事では手法の説明をケーススタディを解くという形で紹介する。
ケーススタディ
サムネでも掲載したが、↓の写真に対しgeolocationをする。(元サイズの画像はこちら)
{kind=link}

ちなみにGoogleレンズを使えば一発で出るのだが、使わない方が調査力が身につくので敢えて回り道をしている。
写真の観察と調査方針の決定
まず、写真内から撮影場所を推定できそうなものを列挙する、高速道路、滑り台と思しきものがあることから公園であることが推測できる。
また、自販機が並ぶ小屋の支柱の位置や影から、小屋の屋根が円形であることが推察できる。
そして、中央に17アイス自動販売機がある。

世の中には高速道路と公園に隣接する17アイス自販機は希少性が高く、この組み合わせで地物のAND検索ができれば一意に定まりやすいのではないかと考えた。
しかし、17アイスの位置はOSMに登録されておらず、overpass turboを用いて一発で検索することはできない。
「overpass turboを使わない」というアイディア
幸い17アイスの自販機の位置(緯度経度)情報は江崎グリコ公式他、有志により公開されている。これらの情報から17アイスの位置情報リストを作ることができる3。
35.7431,139.7868 35.7771,139.6855 35.7034,139.3844 ...
この情報と、OSMに登録されている高速道路や公園の情報を組み合わせればよさそうである。
overpass turboを使うアプローチは難しいが、やりたいことに立ち戻ると「高速道路、公園、17アイス自販機の地理的位置情報のAND検索」ができればよく、そのロジックを書けばよいだけである。
具体的にはoverpass turbo(のバックエンドのOverpass API)だけではできない候補選定処理を、(pythonの)スクリプトサイドで行うことで実現する。
すなわち、
- 17アイス自販機の位置情報リストのうち、位置情報からX m以内に高速道路がある候補を(pythonで)Overpass APIを叩き取得する。
- 手順1で残った位置情報候補のうち、Y m以内に公園がある位置情報をOverpass APIを叩き取得する。
以上である。
文章にしてみれば単純すぎるが、他にもOSMに登録されている地物でフィルタをかけたければステップを追加すれば良いし、登録されていない地物が他にもあれば、地理的距離を計算して候補をふるいにかけるなど、柔軟に処理を書けるメリットがある。
地理位置のAND検索スクリプトの実行
メインロジックの実装例の抜粋を示す(サンプルコード全体はこちら)。
def generate_overpass_query_motorway(gps_latlon): # 位置座標から半径300m以内にある高速道路の候補を取得するOverpassクエリを生成 return f''' [out:json]; nwr["highway"="motorway"](around:300,{gps_latlon}); out; ''' def call_overpass_api(query): # Overpass APIに生成したクエリを投げる overpass_url = "https://overpass-api.de/api/interpreter" response = requests.post(overpass_url, data=query) return response.json() def main(): argvs = sys.argv # 17アイスの位置情報リストファイルを読み込む result_list = [] prefectures = read_gps_list(argvs[1]) try: # 位置1つ1つを見る for idx, gps in enumerate(prefectures): print(idx) # 高速道路と隣接する自販機の数を取得する query = generate_overpass_query_motorway(gps) result = call_overpass_api(query) num = count_num_of_results(result) # 0件の場合はcontinue if num == 0: continue # 公園と隣接する自販機の数を取得する query = generate_overpass_park(gps) result = call_overpass_api(query) num = count_num_of_results(result) # 0件の場合はcontinue if num == 0: continue print(gps) # 最後まで残った候補を結果リストに格納 result_list.append([idx, gps])
実行結果例は以下。
$ python ./src/geoAND_search.py data/coord_17ice_sample.csv result: [1, '35.7771,139.6855'] [7, '35.6726,139.7501'] [8, '35.6333,139.6543'] ... (以下200行程度)
一位に定まることを期待したが、「高速道路、公園、17アイス自販機」が隣接する事例は実際には200件以上あるため、最終的には候補の中から目視で確認する必要がある。
しかし、ここまでの結果は座標情報という形でしか得られていない。
座標を地図アプリに手作業で入力して確認する作業は手間や時間がかかったりオペミスが発生しやすい。ましてや200件をそれで行うことはあまりにも負担が大きい。
そこで次項で効率よく確認する方法を説明する。
位置座標の候補をグラフィカルに確認する
複数の位置座標の候補を目視で大雑把に確かめるための効率的な方法が必要である。
このような場合、Nixintel氏がgeolocationクイズの解法[6]内で使用していた「Google Earth Proのツアーモードでざっと確認する」方法が有効である。
これは、座標候補をGoogle Earthが読み込める形式のファイル(kml)にして、 Google Earth Proで読み込み地図上にピンを刺し、ピンが刺さっている場所の空からの眺めを1個1個スライドショーのような形で確認するというアイディアである。
まず、座標リストをKMLファイルにする必要があるので、chatgptに依頼してpythonスクリプトを書いてもらう(スクリプトのリンクはこちら)。
出来上がったKMLファイルをGoogle Earth Proでロードし、ツアーモードを実行する。
ツアーモードの挙動を動画キャプチャしたので、よろしければ10秒程度、3D酔いに注意して見ていただきたい。
なお正解のピンは動画 00:21 頃のPoint 5 である。
実際には、これを何回も見て、緑の少ない場所の候補を弾いていき、候補から3Dマップを詳細に見て、滑り台と円形の屋根がある候補を根気強く探す。
ここまで調査の時短テクのような論調で語っておきながら梯子を外すようで申し訳ないが、最後は根性である。
候補の座標の絞り込みに時間をかければ、この場所は 足立区都市農業公園であることが特定できる。
今回考えた手法の有効性の考察
1000件を越える自販機の候補から数個に絞れることを期待したが、200件程度残り、そこまで減らなかったと感じる。
その理由は17アイスの設置戦略に公園が含まれるためだと考える。公園に隣接する17アイス自販機はそこまで珍しくないために、絞り込みがそこまで機能しなかった。
また、実際の17アイス自販機の位置はピンの位置からだいぶ遠い位置にある。オープンソースから情報を取ってきたこともあり、いい加減な情報もあり過信は危険ということである。
とはいえ最後の総当たりを行使するうえで労力が減ったことは事実であり、Overpass APIの強力な検索機能をうまく活用できる可能性は示せたと考える。
まとめ
以上、geolocationタスクにおいて、overpass turboを使いたいが、OSMに登録されていない地物を組み合わせたい場合に無理を通す方法を紹介した。
具体的には、Overpass APIとpythonスクリプトを組み合わせることで、通常のoverpass turboでは難しい複合的な位置検索を実現した。また、Google Earth Proのツアーモード機能を活用することで、候補地の効率的な目視確認もできることを示した。
今回の方法によりgeolocation作業の手間を削減できる可能性が期待できる。
17アイスが好きな方々におかれましては、生活圏の漏洩に気をつけつつ美味しくいただきましょう。
参考文献
- [1] GEOINT: Using Overpass Turbo for OSINT | by Predicta Lab | Medium
- [2] Nixintel Open Source Intelligence & Investigations Getting Started With Overpass Turbo – Part 1
- [3] Nixintel Open Source Intelligence & Investigations Getting Started With Overpass Turbo – Part 2
- [4] How to Use Overpass Turbo - GEWEL - Obsidian Publish
- [5] Geolocating Terrorists With ChatGPT | by VEEXH | The Sleuth Sheet | Medium
- [6] Nixintel Open Source Intelligence & Investigations Planes and Cell Masts: A Quiztime Epic
スポンサードリンク
- 「overpass turboを学ぶにはoverpass turboそのものではなく、Overpass QLの勉強が必要」という事実は個人的にとても大事だと思っている。私はoverpass turboの使い方だけをずっと調べていて遠回りしてしまい半年程度は時間の損をした。↩
- また、chatGPTなどにクエリを生成してもらうこともできるが、生成されたクエリはあまり使えないという所感である。例えば登録されていないタグでクエリを生成してしまう。コード生成全般に言えることではあるが、チャットAIにコードを生成させるならば、少なくとも自分でコードの意味が理解できる程度には言語(本記事ではOverpass QL)の勉強が必要だと思う。↩
- 本記事のトピック外のため作り方は割愛する。ちなみに、都内だけで1,000件以上はある。↩
CTF OSINT 問題設計の留意事項

目次
- はじめに
- オープンソースを扱うという性質について
- 調査時の安全性について
- 物理的な安全性
- メンタル面での安全性への配慮
- 調査上の倫理について
- 競技としての公平性について
- 問題の質の確保について
- 調査方法の妥当性
- フラグの妥当性
- 調査する意味を持たせる
- CTFカラーの保持
- その他の要素
- おわりに
はじめに
DIVER OSINT CTF 公式 Writeup が問題設計回りについて割と踏み込んだ内容まで開示していたのを見て、「そういえばCTFにおけるOSINTカテゴリを作る方の話って基本的に xryuseixさんが公開したものくらいしか他にないよな」と思ったので、事例増やしのために、私が過去に Open xINT CTF 2023 作問に携わっていた時の経験をもとに留意事項という形で共有する。
ほとんどはDIVER OSINT CTFの思想に類似しているが、それは実在の人物や組織をターゲットにしたコンテストとして問題の質を追求しようとすると留意する事項が似通うのだと思う。
なお、文中で、"mural"、"cosplayer"、"fireworks"といっているものは私が Open xINT CTF 2023で作問した問題の名前である。
続きを読む