
またSelfie2Animeデータセットを扱ったunpairedな画像変換手法が出てきたので「顔写真 → アニメ顔変換」タスクを中心に手法を理解する。おまけで、コードの簡単な実行方法も説明する。
念の為断っておくが、名にACLと冠しているが自然言語処理のトップカンファレンスとは一切関係ない。
論文の基本情報
- タイトル: 『Unpaired Image-to-Image Translation using Adversarial Consistency Loss』
- 論文 URL: https://arxiv.org/abs/2003.04858
- 論文実装リポジトリ(PyTorch): https://github.com/hyperplane-lab/ACL-GAN
- 著者名: Yihao Zhao, Ruihai Wu, Hao Dong
- 著者所属: 北京大学
ECCV2020 に採択された論文である。今年の採択率は26%。
論文の概要
ソースドメイン(ここでは人の顔写真)の画像からターゲットドメイン(ここではアニメキャラクターの顔)の画像へ変換することに取り組んでいる。GANベースで、unpairedでも(画像の間で対応が取れていなくても)変換できるようにGeneratorを学習させる手法を提案している。
論文が解決したのは下記のCycle GANの欠点である。
- 再構成という制約のために、画像変換時に変換元の画像の情報(ピクセル)を変換先の画像へ埋め込んでしまっている
- 男性→女性変化の時にひげが残っていたりする
- 形状変換能力が弱い
- 顔写真→アニメ変換だと輪郭を変える必要がある
- Cycle Consistency Lossでは決定的な変換しか学習されない
- ある画像をGeneratorに変換するとき同じ画像からは同じ変換しかされない。これは多様性がない。
そこで、入力画像をピクセルではなく特徴として保持しつつも、多様性が生まれるようなlossであるAdversarial-Consistency Lossを提案している。
lossの全体
トータルの損失関数は下記。

はlossの重み付けを行うためのハイパーパラメータである。
第1項目がAdversal-Translation Loss、第2項目がAdversarial-Consistency Loss、第3項目がIdentity Loss、第4項目がBounded focus maskのためのlossである。
説明順はメインの第2項目のAdversarial-Consistency Loss、第1項目のAdversal-Translation Loss、第3項目のIdentity Lossである。なお、第4項目は入力画像を変換する部分を制限するためのlossであるが、selfie2animeタスクにおいては
は0に設定されているので、説明を割愛する。
Adversarial-Consistency Loss
論文のキーポイントとなるAdversarial-Consistency Loss(ACL)に関して説明をする。
このlossがある意図は2つ。
- 1つの画像に対して、多様な変換ができるようにする
- ソース → ターゲット変換のGeneratorに対して、ソースドメインの特徴を保持できるようにする
概念図は下図。元のドメインと別ドメインへ行って返ってきた画像を比較するあたりぱっと見Cycle GANと同じ見た目をしている。

ACLの具体的な式は下記の通り。
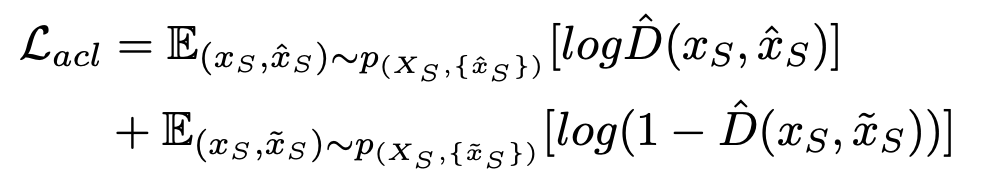
式の構成要素の説明
はACLのために用意されたDiscriminatorである。画像に対して2値分類する分類器である。引数が2つある件は後述する。
は入力画像となるソースドメイン側の画像である。これがオリジナルの画像となる。
は、ソースドメインの画像をターゲットドメインへ変換したフェイク画像である。
は、ターゲット側のフェイク画像を入力として、ソース側に変換したフェイク画像である。
は少しややこしいが、オリジナルのソースドメインの画像に対してターゲットドメインからソースドメインへの画像変換をかけた結果である。Cycle GANでは、これはGeneratorが恒等写像となるように学習されるが、ACL-GANでは下図のように、若干の変化が加わる。このような
を設ける理由は、データオーグメンテーションの役割ではないかと考える。オリジナルの画像
ばかり使うのではなく、そこからノイズでちょっと変換をかけた画像を使う方が多様な変換を獲得できる可能性が高いと著者は考えたのではないだろうか。

は入力画像をターゲット画像へ変換するGenerator、
は画像をソース画像へ変換するGeneratorである。画像のGeneratorはMUNITを踏襲している。すなわち、画像をcontentとstyleに分けるエンコーダーをソースとターゲットの2つのドメイン分用意して、変換時に、ターゲット側のスタイルを混ぜてデコーダーに通して画像を生成している。
は
に従うノイズであり、生成器にノイズを混ぜることで画像のスタイルを多様に変換するための乱数である。これにより、同じ画像を入力してもノイズが異なれば生成される画像も異なるようにできる。
ACLの役割
の大雑把な意味としては、ソースドメインの画像(にSrc→Tgt変換をかけた画像)
と、ソース→ターゲット→ソースと変換2回行ってソースドメインに戻ってきた画像
の差異をDiscriminator
で測っているような形である。
としては、
と
とを見分けようとするし、Generatorは
を騙したいので、これら2つの画像の差異がなくなるように学習していく。
Cycle GANではここを再構成誤差としていたため、1つの画像に対する変換が決定的になってしまう。一方こちらの手法では、識別器で差を測ることで、ソースドメインの画像
と変換して戻ってきた画像
が異なる画像であっても、同じドメインになっていればOKなのでGeneratorが多様な変換を獲得できるようになる。
 はどのように実装されているか
はどのように実装されているか
がxを2つ引数に取る件であるが、これはオリジナルの画像
を連結している。
実際のコードでは、画像をチャネルを軸にして連結している。
例えば画像の入力が[B, C, H, W]として、
一方がtorch.Size([2, 3, 256, 256])で、もう一方もtorch.Size([2, 3, 256, 256])の時、結合時の次元はtorch.Size([2, 6, 256, 256])となる。
画像を連結する意図は、Generatorがソースドメインの元画像の特徴を保持しながら変換する能力を獲得するためのお手本として使用したとのことである(p.6,l.6〜)。
ただ、個人的にはここの設計が不可解である。というのも、で
を混ぜるのではなく、Discriminatorで混ぜているからである。確かにDiscriminatorの分類結果をGeneratorが学習するが、やや間接的ではないかと思ってしまう。
Adversarial-Translation Loss
Adversarial-Translation Loss はいわゆるGANのloss部分である。すなわちGeneratorとDiscriminatorがいたちごっこしている部分である。
ターゲットドメイン側のloss は、下記の通りで、分類器
がrealなアニメ画像
と生成器
が生成したfake画像
を見分ける。

ソースドメイン側のloss はちょっとだけ違う。fake画像が
と
の2つがあるのでlossを折半しているような形。

Identity loss

ここで
,
ACLでは、ノイズを加えることで多様な画像を生成できるようにすると言ったが、自分の画像由来で生成したノイズに対しては恒等写像になってほしいようにloss で制御する。
これにより、期待できることとして下記の4点を上げている。
- 特徴を保持
- 変換画像の質を向上させ、
- 学習プロセスを安定させることを期待する。
- mode collapse(?)を避ける(p.6, 3.3)
- 学習データセットすべてを変換できるようにしようとしてバランスが取れなくて破滅することだろうか?
Generatorのノイズ引数に入れられているは画像をノイズに変換するネットワークとのことらしい。実際のコードを見てみると、下記の手順でMUNITのStyelをAdainのパラメータにしていることを表していた。
- GeneratorであるMUNITのEncoder側でStyleとContentを生成
- Style情報を多層レイヤパーセプトロンに通してAdaINのパラメータを生成
- Decoder側でAdaINの正規化をかけながら解像度を増やして画像にする
- Generatorの画像とオリジナルの画像を、ピクセル差でL1ノルムをとって誤差としている。
実験
U-GAT-IT論文を出した研究グループ(NCSOFT社?)が独自に集めた、Selfie2anime dataset(どこからか収集してきた人の自撮り画像とアニメ画像)で評価する。
比べる手法は、Unpairedな画像変換では有名な所5つ。CouncilGANが最も最近の手法である。Council GANについて興味があれば解説記事を書いたので読んでいただけると幸いである。
定性的な評価は下図。CycleGANと比べると輪郭のデフォルメや顔の追従ができていると主張している。個人的には、他の手法の生成画像とそんなに大差ないという印象。

定量評価結果としてはFID, KIDでどの既存手法にも勝っている。

さらに、U-GAT-ITはパラメータが670.8Mある一方ACL-GANは54.9Mであると主張している。パラメータ数が少ないけど定量評価で勝っていることを強調している。
コードの実行方法
- データセット(U-GAT-IT論文で提供されているもの)
- selfie2anime用コンフィグファイル(有志の人が作成したもの1)
- https://github.com/xunings/ACL-GAN/blob/try_20200916/configs/selfie2anime.yaml
- このファイルを
./configs/selfie2anime.yaml
- 実行コマンド
$ python train.py --config configs/selfie2anime.yaml- もしGPUメモリが足りないならば、configの
batch_size: 3を1に下げると良い。
pretrained weightは提供されていない模様。
追記: 私がモデル学習させた時のpretrained weightを下記に置きました。ただし論文とは異なるパラメータで学習させたため、論文の再現には至りませんでした。 github.com
所感
unpairedな画像変換手法の研究としては着実な進歩を進んでいるが、顔写真→アニメ変換に絞って見ると、限界を迎えていそう。そもそものselfie2animeデータセット自体、データがそんなにが良くない可能性がある(鏡越しの自撮りで顔の前にスマホがあったりする)ので進歩がわかりにくい。だから、selfie2animeタスクに絞って手法を研究開発してほしいところである。
また、目や顔や顔が大幅にデフォルメされなければならない以上、もとの特徴を保持することが好ましくないかもしれない。そう思うと、アニメ調に変換といった時、どんなふうなアニメのスタイルに変換することを期待しているのかを決めて手法を設計した方がいいと思った。
- ただし有志の方のissueによると学習の再現に失敗している模様。著者が原因を調べるといってcloseされている。 https://github.com/hyperplane-lab/ACL-GAN/issues/3↩