
こちらは『創作+機械学習 Advent Calendar 2021』2枚目の2日目の記事です。
先に記事の要旨を説明すると、音声認識器の認識結果を敢えて複数個出力することで韻の近い単語1列(以下フレーズと呼ぶ)を検索するツールとして使えないか検証したという内容です。簡易的に実験した結果、狙ってフレーズを検索するのは難しいですが、面白いフレーズペアを偶発的に発見する用途には使えそうという印象です。
背景
作詞の現場で、押韻を用いた表現を探したい(韻を踏みたい)ケースがあります。例えば「思い出」の母音「o o i e」に近い言葉を探すと「遠い目」という単語が使えそうです。
語彙力が豊富な方やラッパーをなりわいとしている方であれば瞬時に言葉の候補が思い浮かぶのかもしれませんが、経験・スキル・センスが問われる作業だと思います。
そこで誰でも再現できる手順で、似たような音の響きを持つ言葉を探す方法を考えます。
既存手法と課題
考えうる方法としては2つあります。
既存手法1: 過去事例の流用
既存手法の1つめは過去事例の流用です。これはラップの歌詞やMCバトルの書き起こしから使えそうなものをストックしておくというものです。
過去事例の情報源ですが、例えば『韻ノート』には、ラッパーの踏んだ韻を含むラインが第三者により登録されていることがあります。
例えば”R-指定”というラッパーだと次のようなものがあります。
「しかと見ときな格の違い キッズとキングの箔の違い お前殺すぜ覚悟しな ここに転がるカスの死体」
これならば、プロが踏んだ質の良い韻を使うことができそうです。
しかし、この方法で自分の作品を作りたいと思う人はいないと思います。質が良いということはオリジナリティも高く、やみくもに使うと”他人のパクリ”とみなされるためです。作詞作業に限らず創作界隈においてはご法度でしょう。
したがって、他人が踏んでないような韻を探す必要があります。
既存手法2: 母音に基づく検索
既存手法の2つめは母音に基づく検索方法です。
インターネット上には母音で引ける辞書サービスがあります。
たとえば「思い出」と踏みたい韻を探すために、母音“おおいえ”で検索すると、「乙姫」、「とこしえ」というものがヒットします。 また、「五ノ池」のような固有名詞もヒットします。「おおいえ」を母音とする単語単体だけでなく、さらに「おおいえ」を前後に含む単語を検索することができます。
また、"背景"の項目で紹介した「韻ノート」ならば、母音に直さずとも、韻を踏みたい単語で探せます。
試しに「思い出」で検索すると、「暴行事件」「東京事変」などという結果が提示されます。「っ(促音)」や「ー(長音)」を考慮した検索ができるので、現実の発声に即した検索ができます。
既存手法の課題
上に挙げたツールは作詞作業には十分使える一方で限界も2つあると考えます。
1つ目は基本的に1単語対フレーズ(もしくはフレーズ対1単語)でしかヒットしないことです。フレーズ対フレーズではどのようなものがあるかといえば例えば、 『夕方ノスタルジー / ZORN Feat. WEEDY』では「ラムネ の 瓶」と「鳴る メロディ」という韻を踏んでいます。3単語対2単語ですし、単語の切れ目も一致していないので先程の検索ツールではヒットしないでしょう。
2つ目はツールは母音は完全一致のみヒットすることです。 途中に1文字程度の母音が多めに入っていたり抜けていたりというものはヒットしないです。前述の『夕方ノスタルジー / ZORN Feat. WEEDY』では「賃貸マンション」と「心配無いよ」で踏んでいる箇所があります。母音こそ完全一致ではないですが、歌詞の文脈とも合わさって全く違和感がありません。
以上から、既存手法には課題は3点あると考えます。
- オリジナリティが発生しない程度に一般的かつ新規性がありそうなものを探すこと
- フレーズ同士の組み合わせを探すこと
- 音が完全一致でないものも探すこと
提案手法
この課題3つを音声認識エンジンJuliusを使うことで同時に解決できないかと考えました。
核となるアイディアは「Juliusに実装されている、似たような音の響きを持つ単語の候補を時間区間ごとに出す機能を使う」ことです。具体的には下図の"単語グラフ"のようなイメージです。
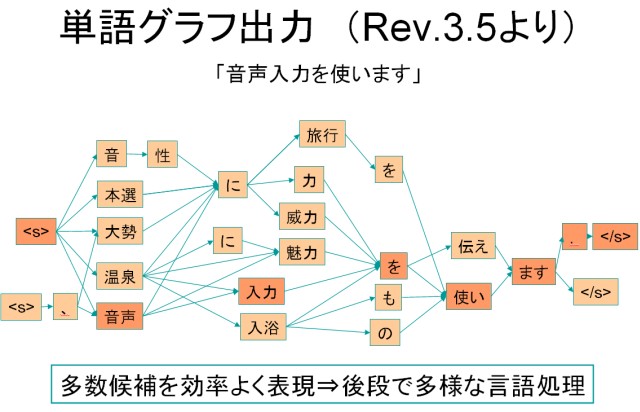
図: 公式ページの"単語グラフ出力"より引用
このような単語の候補のグラフから、韻を踏んだフレーズペアを探すというものです。
Juliusの音声認識アルゴリズム
Juliusを使うとなぜアイディアが実現できるのか、Juliusで採用されている音声認識アルゴリズムの大まかな仕組みを知っていた方が理解しやすいと思うので説明します。(とはいえ他人に説明できるほど音声認識を理解できていないのでやんわりとですが...)
ここで覚えておいていただきたいことはJuliusの音声認識は内部で音響(何と発音されているか)と言語らしさ(言葉としての現れやすさ)をスコア付けするグラフ探索問題を解いているということです。
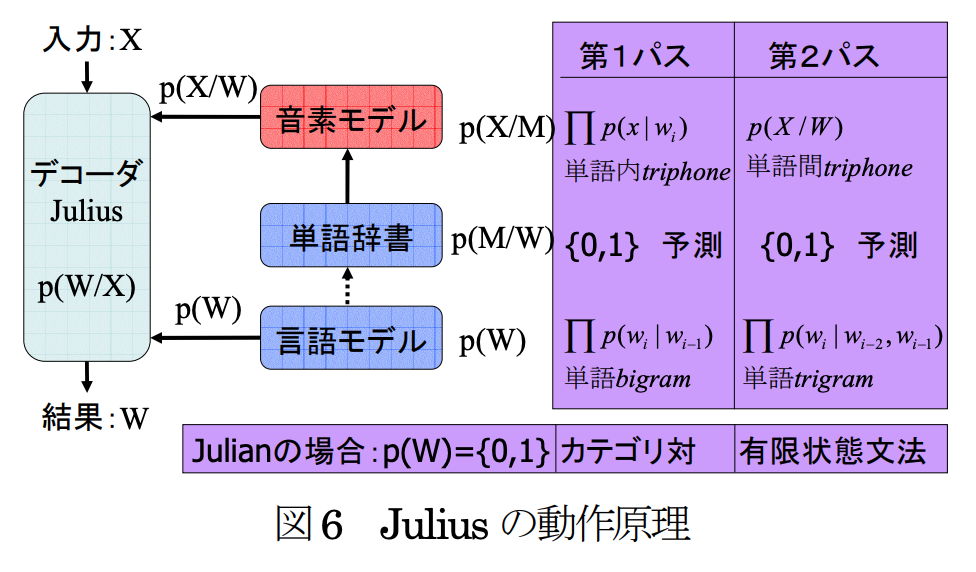
図: Juliusの論文より引用
- 特徴抽出: 入力されたディジタル音声信号から一定時間長で識別のための特徴量を連続的に抽出していきます。JuliusではMFCCという特徴量を抽出します。
- 音素系列の認識: 処理1で抽出した特徴量系列を音響モデル(図で音素モデルと呼んでいるもの)により、音の並びである音素2列を推定します。具体的な処理としては、音素ごとにHMMが用意されており、観測された特徴ベクトルを生成する尤度を各HMMが計算しスコアを算出します。
- 音素列から単語に直す: 音素列は発音辞書を用いて音素列に該当する単語が存在するかをチェックします。
- 発音辞書は次のようなものです: https://github.com/julius-speech/dictation-kit/blob/master/model/lang_m/bccwj.60k.htkdic
- もちろん「a sh i t a」を「明日」とするのか「足 田」とするかという複数の変換先がありますが、そこは手順4で確率的に決めます。
- 単語列の言語的確率を付与: ここまでで、音素列が単語列へと変換されていますので、言語モデルを用いて単語列に言語的観点から単語列の生成確率(スコア)を与えます。例えば「今日 の 天気」と「京都 天気」だと前者の方が確率が高く与えられます。
- 手順2〜4は、どのHMMから通ってきたか、どういう単語に直したかなどで探索経路が異なるため、複数のパスを候補として持ちながら探索を進めます。
- パスの候補の中から一番音響モデルが出したスコアと言語モデルが出したスコアの高いものを音声認識結果として提示します。
Juliusでは2パス探索を採用しており、手順2〜4を2回行います。1パスめでは始点から終点へ順方向に計算処理の軽いモデルでスコアを求めます。2パスめではより前後の文脈に応じたモデルで終点から始点へ逆方向に探索します。このとき1パス目の情報(どの時刻にどういう単語がどういうスコアであったか)をヒューリスティックとして用いることで高速に探索します。
アイディアの再掲
Juliusは音の近さと言語らしさを考慮してグラフの探索問題を解いているという点を説明しました。また、複数の経路を探索候補として保持していることや、いつの時刻に何の単語がありそうかという内部表現を保持している旨を述べました。
ということは、自分が検索したい韻を踏んだフレーズをJuliusに認識させれば、複数の認識結果やJuliusの内部表現から、音の聞こえ方が似ていて日本語としても自然な表現を集めることができるのではないかと思いました。
このアイディアを実現する方法には至ってシンプルで「Juliusの内部表現を出力するオプション3をつけて、踏みたい韻を含むフレーズを発声し、表示された結果をメモする」ことです。
Juliusで実際にフレーズペアを探す
Juliusのセットアップ
大変ありがたいことに、Juliusをすぐに試験できるように”ディクテーションキット”が公式的に用意されています。
”ディクテーションキット”には各OSごとのJuliusのバイナリと、日本語音声認識のためのリソース(学習済みの音響モデルと言語モデルなど)が既に同梱されており、コマンドラインからバッチを実行すればすぐに音声認識を開始することができます。
音声入力手段はデフォルトではマイク入力ですが、実行オプション(-input file)で音声データ4を指定することも可能です。
実験
認識結果上位を表示するように出力
Windows10でrun-win-gmm.batをオプションをつけながら実行してみました。
まず、自分が今踏みたい韻のフレーズを含んだセリフを音声認識し、認識のスコアの上位10つを出力してみます。 ここでは試しに「いい 思い出」に近い聞こえ方のフレーズを探してみます。
「あれはいい思い出だった」と発話した結果を記します5。
sentence1: あれ は いい 思い出 で 、 だ 。 sentence2: あれ は いい 思い出 って 、 だ 。 sentence3: あれ は 入り 思い出 って 、 だ 。 sentence4: 、 あれ は いい 思い出 で 、 だ 。 sentence5: あれ は 入 思い出 で 、 だ 。 sentence6: 、 あれ は いい 思い出 って 、 だ 。 sentence7: R Y いい 思い出 で 、 だ 。 sentence8: あ 、 あれ は いい 思い出 で 、 だ 。 sentence9: R Y いい 思い出 って 、 だ 。 sentence10: あ 、 あれ は いい 思い出 って 、 だ 。
本来見つけたかった「いい 思い出」の部分はどの結果でも正しく認識されており、フレーズペアを見つけることに失敗しました。敢えて言うなら「あれ は いい」と「R Y」がフレーズ対フレーズのペアなのですが、歌詞として使えるケースは極めて限定的でしょう。
”単語ラティス形式”で出力
複数の認識結果を見ることは目が疲れるので、”単語ラティス形式”で出力(オプション-latticeをつけて実行)をしてみました。こちらは、どの区間にどのような単語がありそうかを可視化できるものです。
先程と同じく「あれはいい思い出だった」と発話した結果を記します。
-------------------------- begin wordgraph show ------------------------- 0: 0:|-| 1: 0:|------| 2: 0:|-------| 3: ああ 7: || 4: あ 7: || 5: あー 7: || 6: 、 7: |-----| 7: 、 10: |---| 8: タレ 20: |--------| 9: たれ 20: |--------| 10: 多衣 20: |--------| 11: 佐江 20: |--------| 12: 幸い 20: |-----------------| 13: は 21: |---| 14: 彼 21: |-------| 15: あれ 21: |--------| 16: 彼 21: |--------| 17: かれ 21: |--------| 18: カレー 21: |--------| 19: 我 21: |--------| 20: われ 21: |--------| 21: 姉 21: |--------| 22: 吾 21: |--------| 23: 金 21: |--------| 24: 腫れ 21: |--------| 25: あれ 21: |--------| 26: 晴 21: |--------| 27: 綾 21: |---------| 28: 彩 21: |---------| 29: 亜矢 21: |---------| 30: アレン 21: |----------| 31: カレン 21: |----------| 32: 亜鉛 21: |----------| 33: か弱い 21: |----------------------| 34: 良い 32: |------------------| 35: の 43: |------| 36: は 44: |------| 37: は 47: |-----| 38: は 49: |----| 39: いい 62: |------| 40: いい 66: |----| 41: 思い出 79: |----------------| 42: だっ 122: |-----------| 43: た 151: |-----| 44: 。 168: |-| -------------------------- end wordgraph show ---------------------------
やはり「いい 思い出」の部分はまとめられてしまっています。しかし、「あれ は いい」の部分に「か弱い」という表現が出てきました。母音が完全一致していないですが似たような響きの単語が偶発的に得られたと思います。
考察
自分が見つけたい韻のフレーズをピンポイントでみつけることは難しそうです。それは尤もなことで、認識結果の上位に来るものは当然似た認識結果になりやすいです。もっとスコア付けをオプションで調整し、「聞き間違え」を意図的に誘発して認識結果の多様性を上げる必要がありそうです。
このような理由から、フレーズの検索用途というよりも、何らかの音声を”単語ラティス形式”形式で垂れ流しておき、作詞に使えそうなフレーズペアを偶発的に発見してそれをストックする用途の方が適しているのではないかと思います。
私の手法のその他の限界としてはJuliusの学習モデルの制約が考えられます。例えば語彙は bccwj.60k.htkdic 内の単語に制限されています。このファイルに単語を追加することもできますが、言語モデルには含まれていないため、未知語の確率が割り振られ認識結果に出る確率が下がり認識結果としてヒットしにくいです。また、音素の連節(トライフォン)もlogicalTriというファイルで定義されており、このファイルに載っていない音素列を含む単語は登録することができません。このように、キットを改造するには音声認識への理解やエンジニアリングが必要で高い技術力が要求されそうです。
まとめ
音声認識エンジンJuliusを用いて、フレーズ同士の韻を踏んだ表現を検索(あるいは収集)する方法について提案しました。
探したい韻のフレーズを検索する用途に用いるのは必ずしも成功しないですが、実際に作詞に使えそうなネタを偶発的に発見する用途としては使えそうであることがわかりました。もちろん作詞活動だけでなく漫才の聞き間違えネタに使えそうで、コメディと相性がよさそうです6。
今回は音声認識モデルでしたが、他のタスクも同様に認識結果のうち次候補以降や推論ミスも面白い用途に使えるかもしれません。
それでは、最後まで記事を読んでいただきありがとうございました。
追記:
再掲になりますが、『創作+機械学習 Advent Calendar 2021』では、創作活動用途に機械学習技術を適用する取り組みを有志が多数公開してくださっています。どの記事も面白いので、ぜひラインナップを一読いただければと思います。